什么是文本清洗
文本清洗(Text Cleaning),也称文本预处理,是在进行 NLP 任务前,对原始文本数据进行规范化、结构化的过程,目的是把混杂的原始语料转化为干净、标准化的格式,为后续的情感分析、主题建模、关键词提取等任务打基础。
NLP 领域有一条基本原则:垃圾输入,垃圾输出(Garbage In, Garbage Out)。模型再先进,数据不干净,结果就不可信。
哪些语料需要清洗
除了经过专业人工校对的结构化语料外,绝大多数文本都需要预处理。以下是城市研究中最常见的四类:
| 语料类型 | 典型问题 | 清洗重点 |
|---|---|---|
| 社交媒体 UGC(微博、小红书、点评) | 拼写随意、句子碎片化、表情符号、话题标签、广告 | 噪声去除 + 语义还原 |
| 网页爬取文本(新闻、门户网站) | HTML 标签、导航栏、广告代码、版权声明 | 强力清理 + 语义还原 |
| 政策文件与学术文献 | 页眉页脚、目录、引用标记、参考文献 | 自定义停用词 + 长文本分割 |
| OCR 文本(历史档案、扫描件) | 错字乱码、段落错乱、字形误识 | 视原件质量选择步骤 |
举个例子,这条微博里真正有分析价值的只有一句话:
#老城区改造# 太赞了!!!终于不用走那条烂路了哈哈哈哈[笑哭][笑哭] @某某某
话题标签、表情、@ 提及、重复字符都是需要剥离的噪声。
城市研究特别提醒:政策文本里的"根据""有关""进一步"等词,在通用文本中不算停用词,但在主题建模时会形成干扰,需要通过自定义停用词表处理。
文本清洗分两步走
步骤一:噪声去除(Noise Removal)
剔除表层的、通用的噪声:停用词("的""了""是""在")、标点符号与特殊字符、多余空格与重复内容、残留的 HTML 标签与格式代码。
步骤二:语义还原(Semantic Restoration)
噪声去除后,文本有时会变得更难分析。因为话题标签、标点符号虽然是"噪声",也是隐性的结构标记——它们隔开了不同的话题和句子。清除后,内容会粘成一长串无法断句的流水账。
语义还原用 AI 模型重新理解文本的内在逻辑,恢复合理的断句与分段,把混乱内容还原为结构清晰、语义完整的文本。
⚠️ 关键顺序:先噪声去除,再语义还原
如果顺序反了,AI 模型会被噪声干扰,生成错误的断句判断。这个顺序不可颠倒。
是否两步都做?分场景判断
| 语料类型 | 噪声去除 | 语义还原 |
|---|---|---|
| 政策文件、学术文献 | ✅ 需要 | ❌ 通常不需要 |
| UGC、网页爬取文本 | ✅ 需要 | ✅ 需要 |
| OCR 文本(原件质量好) | ⚠️ 视情况 | ✅ 需要(修复段落) |
| OCR 文本(原件质量差) | ✅ 需要 | ✅ 需要 |
TATOOLS 操作教程一:噪声去除
打开 tatools.cn,登录后进入标准文本处理模块,找到"文本清洗"功能。此处支持 txt 与 csv 两种输入格式:txt 对整份内容统一清洗,csv 按列对每个单元格分别执行同一套清洗流程。
第 1 步:上传文档
点击上传文本导入待处理文档。

TATOOLS 内置了一套默认基础清理,自动完成、无需手动设置,包括去除 emoji、零宽字符、控制字符、行/段落分隔符等隐性字符。这类字符普遍存在于网页和 UGC 中,保留会干扰后续分析。
第 2 步:配置清洗参数
参数 A:是否移除停用词
- 作用:移除常见无意义词汇(的、了、是、在等)
- ✅ 建议默认开启
- 📌 支持上传自定义停用词表(适合政策文本、特定领域语料)
- 格式要求:txt 文件,每行一个词

参数 B:标点符号处理(二选一)
| 选项 | 适用场景 |
|---|---|
| 删除全部标点 | 词频统计、关键词共现分析 |
| 删除全部标点,保留常用标点(。?!) | 情感分析、句子级分析 |
如果后续要做句子分析,必须保留标点来维持句子边界。
参数 C:是否开启强力清理
- 作用:清除隐藏格式、冗余代码、特殊编码
- ✅ 适合:网页爬取文本
- ❌ 不适合:格式规范的政策文件或学术文献(会误删有效内容)
参数 D:是否分割长文本
这一选项是为主题建模准备的。LDA、BERTopic 等算法要求每个文档主题相对集中,整份长文档输入很难提炼出清晰主题。
| 后续算法 | 推荐窗口大小 |
|---|---|
| LDA | 几十到一两百字的短段 |
| BERTopic | 一百到几百字的段落 |
| 短文本语料(微博、在线评论) | 不需要开启 |
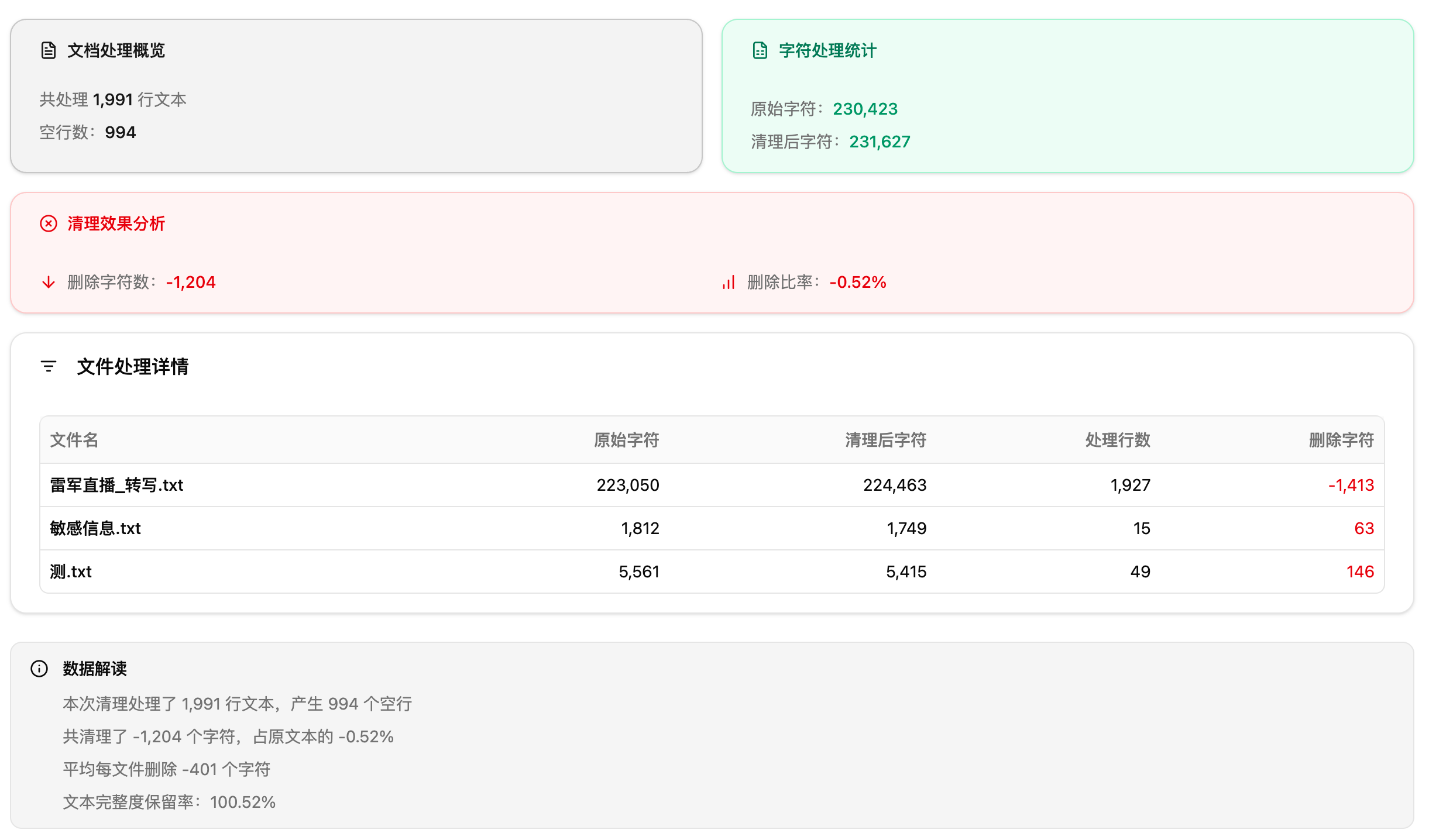
第 3 步:提交并查看清洗报告
确认参数后提交任务。系统处理完成后会自动生成一份清洗报告,包含处理前后字符数对比、移除项统计等。
清洗完成后必做:抽样验证
不要盲目信任自动化处理的结果。建议按以下流程验证清洗质量:
- 从清洗后的语料中随机抽取 10–20 条
- 逐条与对应的原始文本比对
- 检查是否存在过度清洗(删掉了有用信息)
- 检查是否存在清洗不足(噪声没清干净)
- 确认自定义停用词表是否漏词或误伤
- 对分割后的文本,确认窗口大小是否合理(过短会导致主题分散,过长会导致主题模糊)
- 发现问题后回到参数设置区调整,重新处理
常见问题
Q: 政策文本分析时"根据""有关"要不要过滤?
视任务而定。做词频统计或主题建模时建议过滤,因为它们会形成高频干扰;做政策语言风格分析或修辞研究时需要保留。
Q: 清洗会影响情感分析的准确率吗?
会,而且影响很大。建议保留常用标点,不要过度清洗,否则会丢失语气和情感边界。
立即开始 · 访问 tatools.cn 上传你的第一份语料