词性标注做的事情是:给文本里的每个词分配一个语法类别,然后从整体上统计各类词性的分布情况。
处理过程大致分四步。
- 先做分词和语言识别。中文文本用分词工具切词,英文直接按空格和标点切分。系统会自动判断文本是中文、英文还是中英混排。
- 然后跑标注引擎。中文文本同时用两套引擎:一套基于分词工具,覆盖 60 多种细词性;一套基于句法分析器,覆盖 200 多种细词性。英文只走句法路径。
- 接着做粗类归并。分词路径和句法路径的细粒度标签会分别映射到统一粗类。中文分词路径主要归并为 14 个粗类:名词、动词、形容词、副词、代词、数词、量词、介词、连词、助词、语气词、叹词、方位词、其他。句法路径和英文路径会保留原始细标签,同时提供可对照的粗类统计。这个归并降低了分析门槛,方便横向比较。
- 最后生成报告。包含词性分布柱状图、跨文件热力图、转移概率矩阵、基准语料对比、例词展示,以及按词性筛选的 CSV 导出和实词词典 TXT 导出。
两套引擎的结果不一定完全一致,这很正常。分词路径更贴近中文分词习惯,句法路径更贴近语法角色。两条路径的标签集合不同,不能直接当一致率解读,但可以互相参照。
适用文档
目前支持 TXT 文件输入。编码建议用 UTF-8,其他编码出现乱码可以先转一下。
语言方面,中文和英文都支持,中英混排也可以处理。系统会自动识别语言后分别用对应的引擎标注。
输出结果包括报告页面、词性明细 CSV、筛选结果 CSV 和实词词典 TXT。
适用情景
- 语料库语言学研究。标注词性分布特征,对比不同语体的语法差异,建立语料库的词性基线。比如对比学术论文和访谈转录稿的名词占比差距。
- 文本风格分析。通过词性占比判断文本偏口语还是偏书面、偏正式还是偏随意。在访谈、对话和评论类文本中,代词和语气词占比偏高,通常有助于判断口语化特征。
- 翻译质量评估。对比原文和译文的词性分布差异,发现翻译中的语法偏移和修饰语冗余。形容词占比异常偏高可能是翻译腔的信号。
- 文本分析预处理。为后续句法分析、实体识别、关系分析等任务提供词性参考。词性标签是很多分析管线的基础输入。
- 教学研究。分析学生作文的词性使用模式,发现语法薄弱点。比如动词形式单一可能说明表达不够丰富。
使用步骤
第一步:上传文件。你可以上传一个或多个 TXT 文件,系统逐个处理。
第二步:确认处理设置。上传后页面会显示处理设置区域,默认配置通常适合一般文本。需要术语识别、停用词过滤或导出筛选时,可以在这里调整,具体含义在下一节展开。
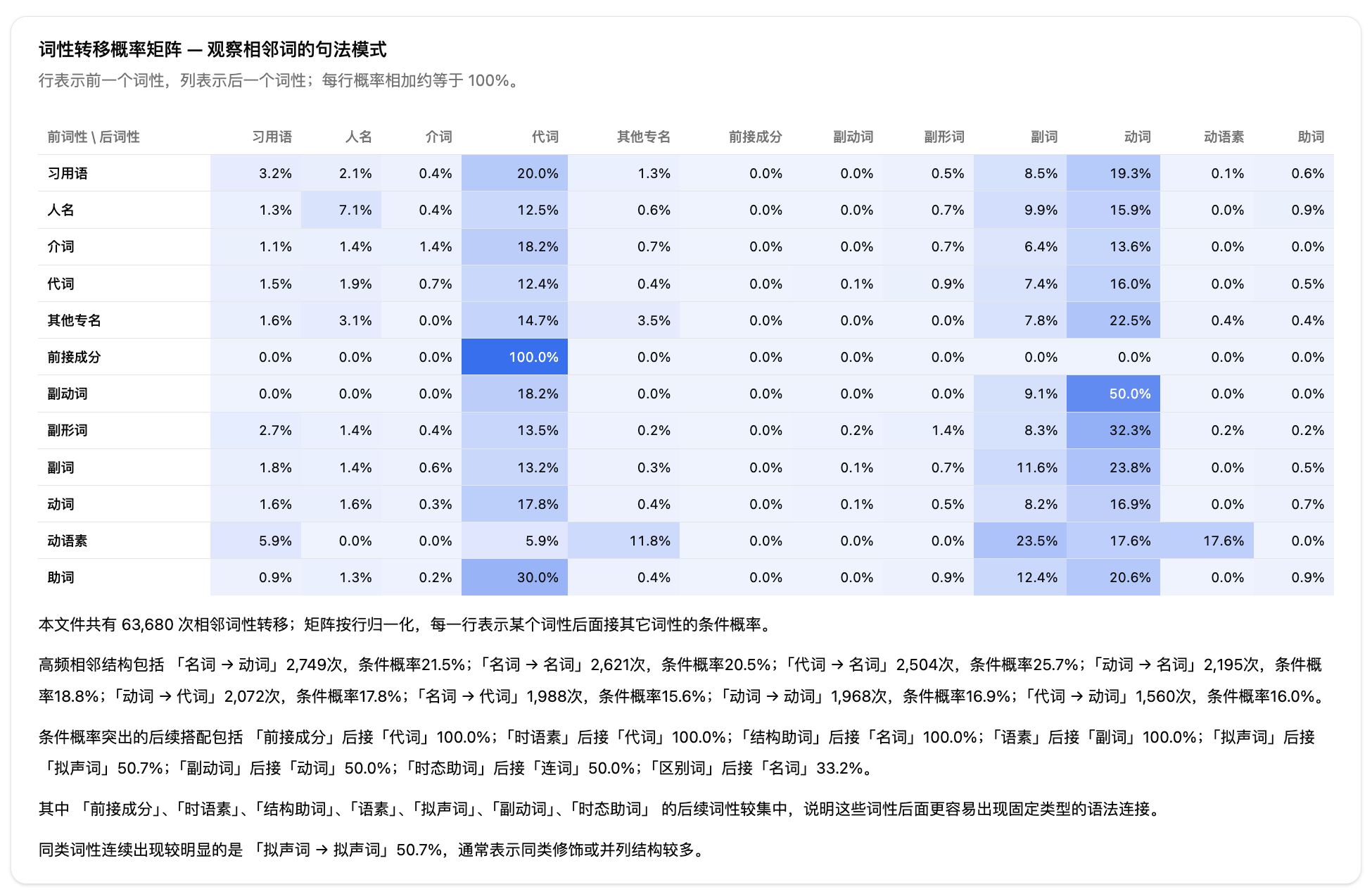
第三步:查看报告。提交后系统自动处理,完成后跳转到报告页。报告包含数据解读卡片、筛选导出区、跨文件热力图、基准对比、分词路径和句法路径的柱状图、转移概率矩阵、示例词等模块。

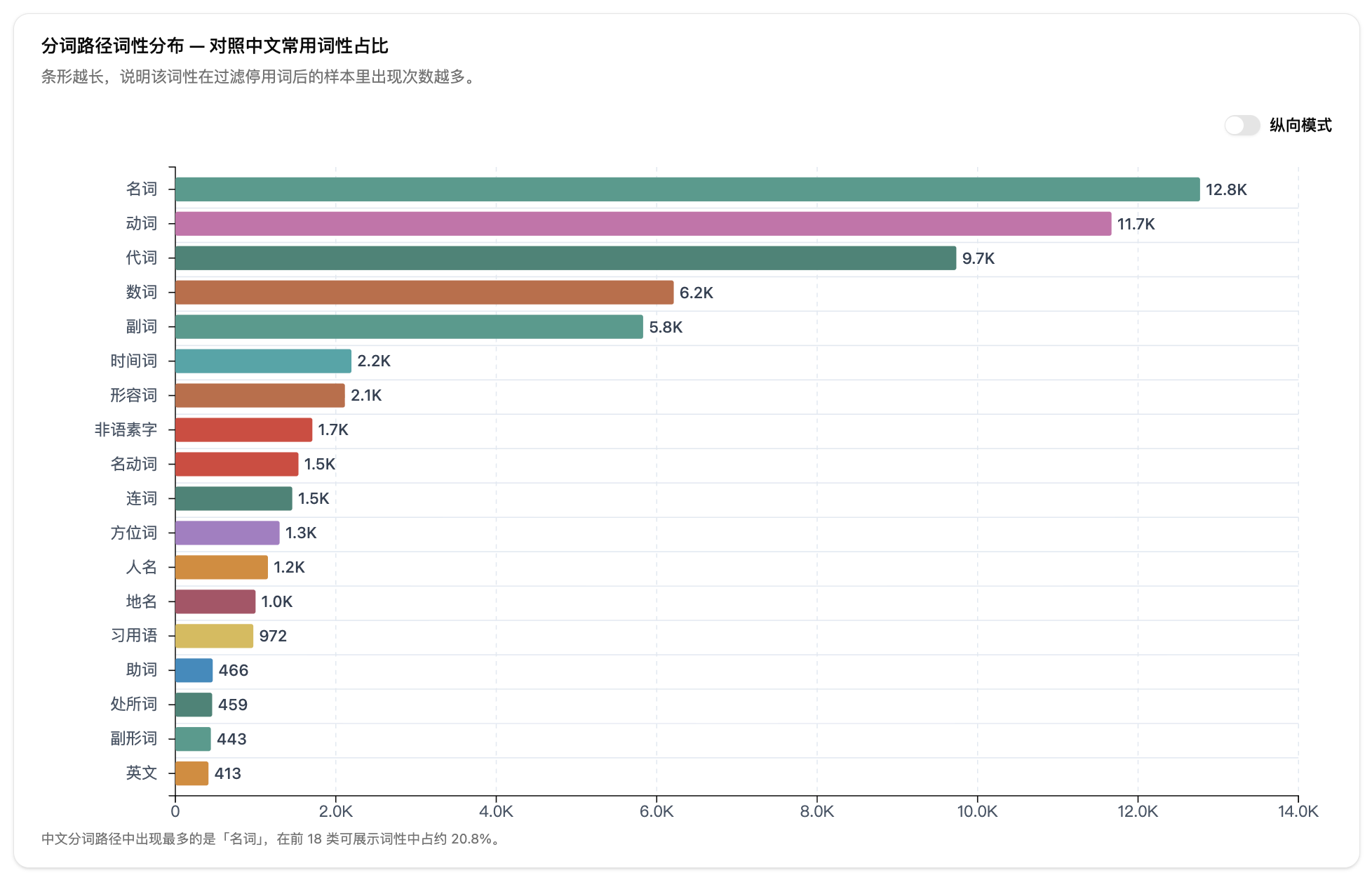
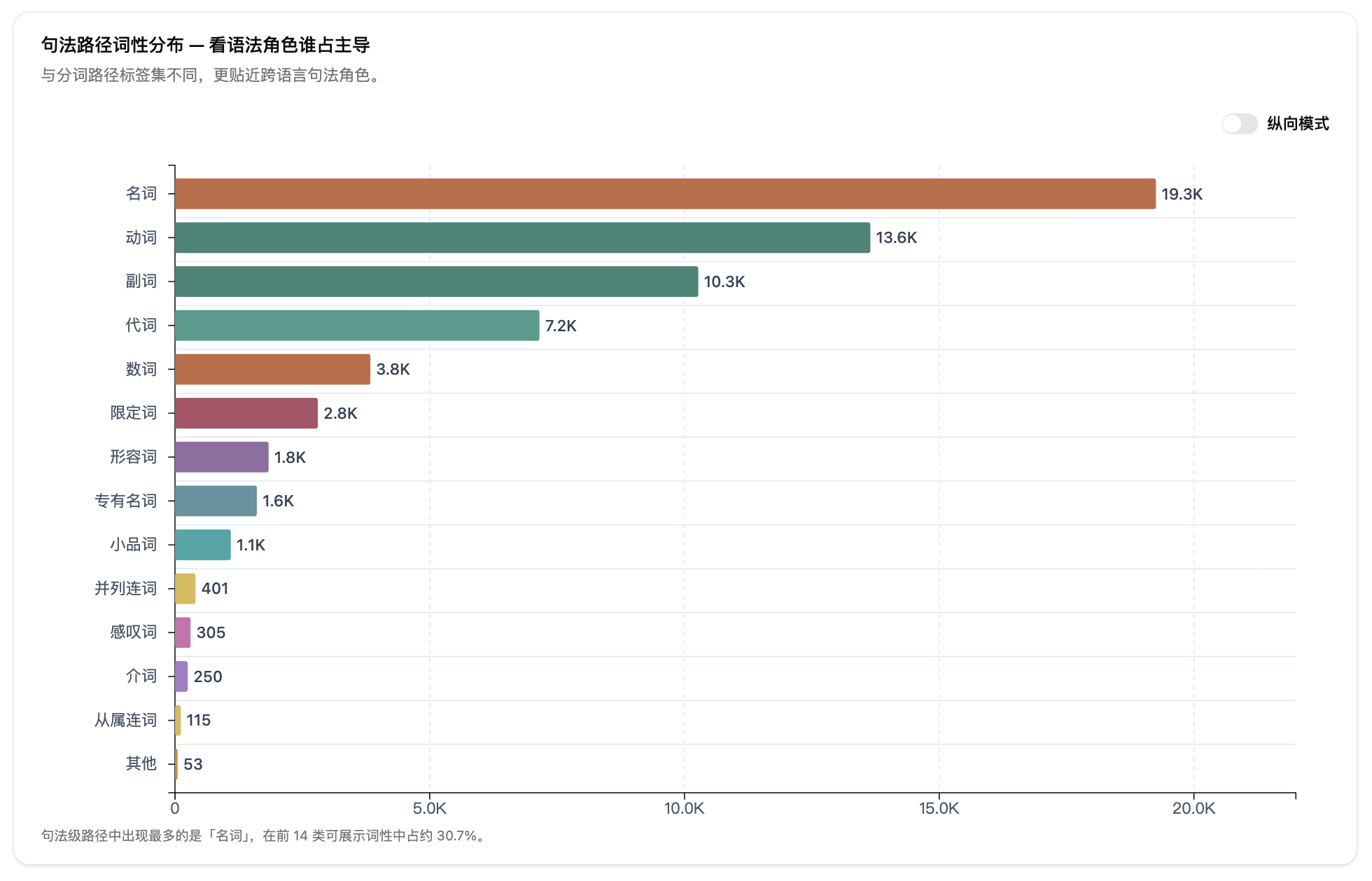

第四步:导出结果。在筛选导出区选择标注路径和要保留的词性类别,可以导出筛选结果 CSV 或实词词典 TXT。下载包里还包含每个文件的词性明细。

参数解析与对比示例
可配置参数如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 文档主要语言 | 中文或英文。用于设定默认处理策略,系统会在此基础上识别文本片段中的语言并分别处理。若整篇文档为英文,建议切换为英文 | 中文 |
| 使用自定义字典 | 上传自定义词典文件,每行一个词,帮助分词工具识别专有名词和术语 | 关闭 |
| 使用自定义停用词 | 上传停用词文件,每行一个词,在分词后、统计前过滤这些词 | 关闭 |
| 分词模式 | 精确模式(互不重叠)、全模式(扫描所有可能词语)、搜索引擎模式(精确基础上补充搜索词) | 精确模式 |
| 智能词汇识别 | 自动发现语料中的新词,补充分词词典。比较耗时,仅在前一定字数内启用 | 关闭 |
| 词性过滤 | 勾选要排除的词性类别,标注完成后从统计和导出结果中排除这些词性 | 关闭 |
| 基准语料类型 | 选择用于对比的参考语料:一般新闻、学术、口语、社媒、电商评论、文学作品 | 一般新闻 |
| 导出标注路径 | 选择分词路径或句法路径用于导出 | 分词路径 |
| 导出词性范围 | 选择导出时保留的词性类别 | 名词、动词 |
三组典型配置供参考。
- 基础标注。语言选中文,其他参数保持默认。适合大多数中文文本的快速标注,两套引擎同时跑,结果可相互参照。
- 术语强化标注。开启自定义字典,上传领域术语词典。适合包含大量专业术语的文本,比如医学、法律、IT 领域文档,能减少术语被错切的情况。
- 内容词聚焦标注。开启词性过滤,勾选介词、连词、助词、语气词等功能词类别。适合只想看实义词分布的场景,过滤后柱状图和导出词表更干净。过滤后,图表和导出结果只反映保留词性的分布,不再代表全文完整词性结构。
分词模式的选择影响分词路径的结果。精确模式适合一般分析,全模式会产生冗余但覆盖更全,搜索引擎模式介于两者之间。句法路径不受分词模式影响。
案例分析
案例一:社科访谈文本语法分析。
背景:某团队对 200 份深度访谈转录文本做词性标注,想了解口语语料的语法结构特征。
配置:语言选中文,其他参数默认。
结果:分词路径显示名词占比约 36%,看起来跟学术语料差不多。但转移矩阵中「代词→动词」的相邻搭配比书面语更常见,语气词和叹词占比高于所选学术参考线。基准对比中选择「口语语料」参考线后,偏差明显缩小。
结论:单看词性占比可能会误判语体特征。转移矩阵和功能词占比才是区分口语和书面语的关键指标。
案例二:中英混排论文语料对比。
背景:某语言学实验室上传 50 篇中英混排论文,想比较中英文部分的语法差异。
配置:语言选中文,开启自定义字典上传学科术语。
结果:系统自动识别语言后分别用两套引擎标注。跨文件热力图显示各文件的词性分布相对一致。基准对比中选择「学术语料」参考线,中文部分的名词占比约 38%,低于英文参考值,但形容词占比偏高。回看原文和译文片段后,团队发现部分句子存在修饰语堆叠现象,这可能解释了形容词占比偏高。
结论:中英混排文本可以分别标注后横向比较。中英文部分的词性比例可以在统一粗类下观察趋势,但不建议把百分比差异直接解释为语法强弱差异,需要结合分词粒度和文本类型复核。
类似功能对比
词性标注和分词、关键词抽取看起来都跟"词"有关,但做的事情不一样。
| 词性标注 | 分词 | 关键词抽取 |
|---|---|---|
| 给每个词标语法类别,统计分布 | 把连续文本切成词语 | 提取文本中最重要的词或短语 |
| 语法结构、词性比例、相邻词性搭配 | 词语边界、切分准确性 | 词的重要程度、主题相关性 |
| 词性分布、转移矩阵、基准对比 | 分词结果、词表 | 关键词列表、权重排序 |
| 语料库研究、风格分析、翻译评估 | 分析预处理、词频统计 | 主题分析、标签生成、摘要提取 |
三者可以组合使用。词性标注完成后,可以在名词、动词等指定词性范围内做关键词抽取,让结果更聚焦。