使用教程
学习如何使用各项功能,快速上手
 文本分析基础教程
文本分析基础教程DeepSentiV2 情感分析教程:按语境判断整句倾向
DeepSentiV2 用整句语义而不是单个褒贬词判断情感。每条有效文本会得到积极、中性或消极标签、0 到 1 的得分,以及最多五个关键词。工具还提供七种行业文本类型,让同一句表达放回更贴近业务的语境中分析。下面从文本粒度、参数选择、报告阅读和两组实测样本说明具体用法。
 文本分析基础教程
文本分析基础教程传统情感分析工具使用教程:对比两种词典方法,补充自己的情感词表
传统情感分析基于 PySenti 和 CnText 两个开源词典方法做二次开发,底层词典融入了多年实际项目中积累的行业情感词。它适合做评论、问卷开放题、舆情短文本和访谈分段的初步正负中标注。这个工具的重点不是自动理解复杂语境,而是把两种词典方法放在同一份报告里对比,并允许用户自己补充积极词和消极词。你可以用它查看 PySenti 在默认词典和自建词典下的变化,同时把 CnText 作为另一套内置情绪词典口径参考,再把分歧样本交给人工复核。
 文本分析基础教程
文本分析基础教程文本矩阵分析工具使用教程:给多份材料定核心词、看词与词怎么抱团
文本矩阵分析适合回答一个问题:这批材料里哪些词最值得关注,它们之间又是怎么抱团的。你上传多份 TXT 或 CSV,系统会先把文本切成一段段「文档段」,统计词频并做 TF-IDF 加权,挑出在这批材料里区分度最高的核心词;再看这些词在同一段里谁和谁反复结伴出现,连成共现矩阵和关系网络。它不替你归纳主题,而是给你一份按重要度排好的词表、一张谁与谁结伴的热力图,以及每个词对回原文核对的证据,帮你决定从哪里开始读、从哪里开始编码。
 文本分析基础教程
文本分析基础教程依存句法分析工具使用教程:可视化句子骨架,量化句式复杂度
依存句法分析适合回答「这句话的结构是什么样的、哪里让读者读不懂」。编辑处理长难句时需要定位主干,老师讲解句式时需要可视化结构,研究者对比句式复杂度时需要量化指标——这些场景的共同点是:不能只靠语感判断句子结构,还需要看得见的骨架和可比较的数字。这个工具会逐句标出主语、谓语、宾语和修饰成分之间的依赖关系,用可视化依存关系图呈现句子结构,并给出句法复杂度评分。
 文本分析基础教程
文本分析基础教程词语共现分析工具使用教程:用统计指标判断词对搭配是否可靠
词语共现分析适合回答「哪些词经常一起出现,这种搭配是否稳定」。做舆情分析时需要梳理话语口径,做访谈研究时需要提取概念关联,做知识图谱时需要准备搭配数据——这些场景的共同点是:不能只看单个词的频率,还要看词和词之间的关系。这个工具会在指定窗口范围内扫描词对,用三种统计指标判断搭配是否超出随机水平,帮你从文本里提取可靠的词语搭配结构。
 文本分析基础教程
文本分析基础教程文体风格指纹工具使用教程:把写作习惯拆成可对比的风格画像
文体风格指纹适合把模糊的写作读感拆成具体指标。老师觉得作文有点散、编辑觉得改稿没改到位、审稿人觉得论证不够连贯、运营觉得通稿语气不统一——这些判断往往是对的,但落到修改时还需要更具体的依据。这个工具会从句长、句型、词汇结构、词性占比、标点密度和人称代词使用率等维度生成写作画像,让每个角色的读感都能落到可修改的指标上。
 文本分析基础教程
文本分析基础教程命名实体识别工具使用教程:从文本中提取人名、地名、机构和时间线索
命名实体识别适合在正式分析前整理对象清单。它会从 TXT 或 CSV 文本中提取人名、地名、机构名、时间等专名线索,并保留实体所在原句、实体类型、开始位置和结束位置。报告页会同时展示规则识别和语义识别两种口径,上方先给出整体解读,下方用高频实体和句子级对照表帮助你回到原文复核。这个功能不替你判断人物关系或事件因果,它的价值在于把散在文本里的对象先整理出来。
 文本分析基础教程
文本分析基础教程高频词提取工具使用教程:统计词频和固定词组,找出文本中反复强调的核心提法
写报告、做分析的时候,你可能想知道一篇文章里哪些词被反复提到、哪些说法经常连在一起出现。靠人工通读很难精确量化,靠AI读也不行——容易有幻觉,遗漏或编造根本不存在的提法。高频词提取解决的就是这个问题:统计单个词的出现次数,也可以在你勾选两个词、三个词、四个词组合后,统计相邻词组成的固定词组。报告会自动给出关键发现,配上词云、面积图、Top 20 清单和「核心词 × 长组合」对比表;多文件时还会展示跨文档共有词和单篇独有词。
 文本分析基础教程
文本分析基础教程关键词抽取工具使用教程:TF-IDF 和 TextRank 双算法交叉验证,提取文本核心关键词
一篇文章里哪些词最能代表它的主题?单靠一种算法可能会有偏差。关键词抽取同时运行 TF-IDF 和 TextRank 两种方法,TF-IDF 看稀有度,TextRank 看关联强度,再自动计算排名相关系数,帮你在交叉验证中找到最可靠的关键词。
 文本分析基础教程
文本分析基础教程词性标注工具使用教程:统计词类分布,分析文本语法特征
文本中的名词、动词、形容词比例,会影响我们对文体风格的判断。词性标注会把每个词归入语法类别,再汇总为分布统计、相邻词性转移矩阵和基准语料对比。中文文本同时跑两套标注引擎,结果可以相互参照,帮助发现分词路径和语法角色判断上的差异;英文走句法级路径,标签集更贴近跨语言语法体系。
 文本分析基础教程
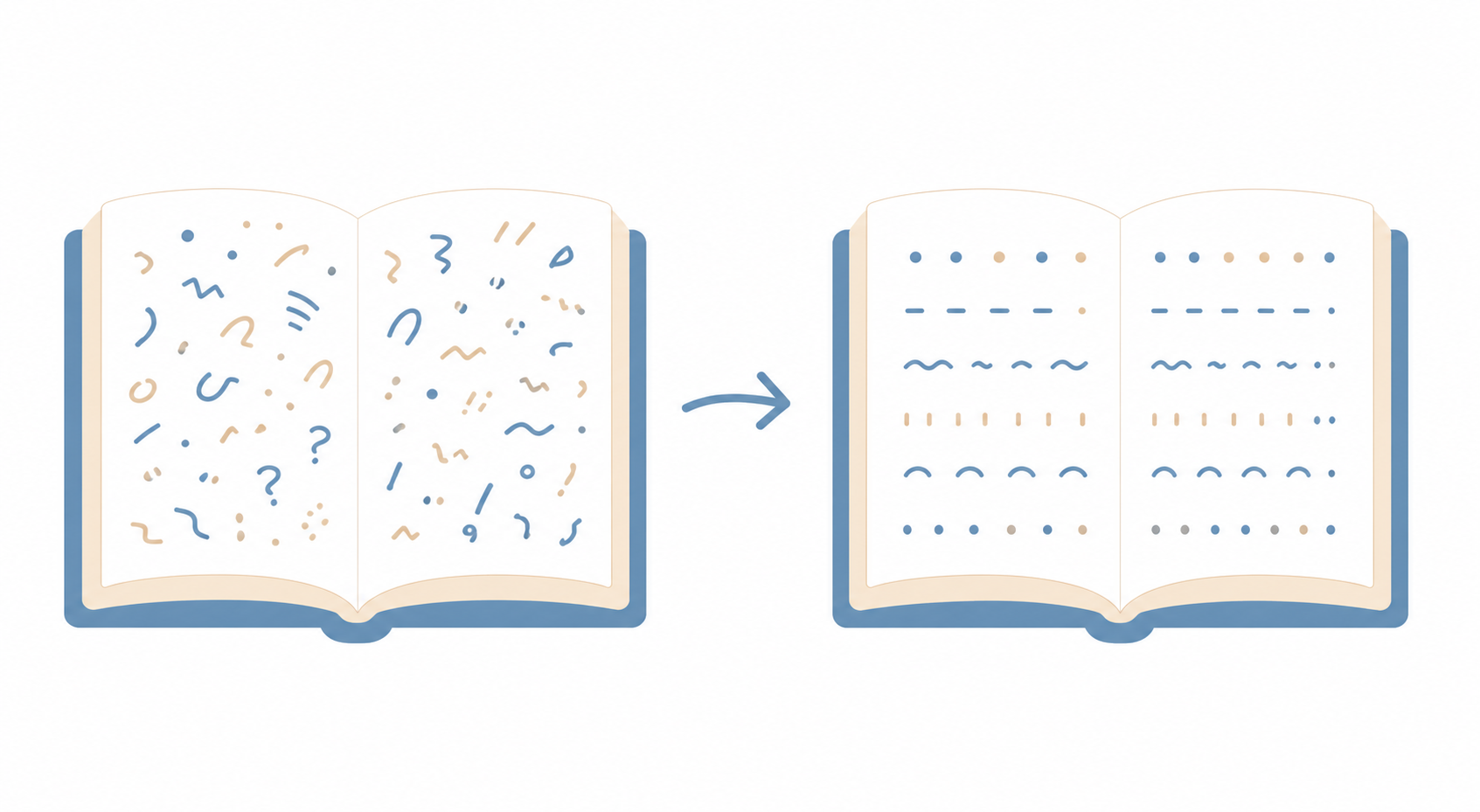
文本分析基础教程文本质量评估器:从字符构成到任务适用性,给语料做一次全面体检
你手头有一份文本,想拿去做主题建模或者情感分析,但不确定质量够不够。符号太多会不会让分词崩?重复行太多会不会让主题模型全是噪声?文本质量评估器帮你回答这些问题。它用纯统计方法(不调用大模型)从字符构成、词汇丰富度、重复率、句长分布、信息熵等多个维度给文本做一次量化体检,输出一份 0-100 的综合得分和六种 NLP 任务的适用性判定。
 文本分析基础教程文本规范化文本清洗
文本分析基础教程文本规范化文本清洗中文文本规范化工具使用教程:繁简转换、标点统一、数字转正文、拼音转写
不同来源的中文文本,繁简体、标点符号、数字写法经常不一致。人工阅读时不太显眼,但做排版发布或者文本分析时会出问题——同一个词在简体和繁体里变成了两个词条,词频统计就散了。中文文本规范化帮你把这些不一致统一起来,处理方式是无损替换,一个字都不会丢。和文本清洗不同,规范化是"改写",清洗是"删减",建议先规范化再清洗。
 文本清洗文本分析基础教程
文本清洗文本分析基础教程文本清洗工具使用教程:批量去除噪声、标点、停用词,输出干净语料
原始文本里经常混着 HTML 标签、多余标点、emoji、零宽字符这些东西。它们会干扰词频统计、主题建模、情感分析的结果。文本清洗帮你把这些噪声批量去掉,处理完得到干净文本和一份对照预览,方便你确认没有误删。
TATOOLS 用户隐私政策