词语共现分析做的事情是:在文本中设定一个滑动窗口(左右各 2~15 词),扫描窗口内哪些词反复一起出现,然后用统计方法判断这些共现是否可靠。
处理过程可以理解成三步。
- 先扫描共现。系统把文本切成词,在每个窗口范围内记录同时出现的词对。支持 2 词、3 词、4 词共现。窗口越大,捕捉的搭配范围越广,但也更容易引入噪音;窗口越小,搭配越精确,但可能遗漏距离稍远的关联。
- 再计算指标。对每组词对同时给出三种判断:互信息看共现频率是否远超随机水平,T 值看搭配是否具备统计显著性,对数似然比看搭配在文本中有多稳定。三种指标各有侧重,综合判断比单看一个更稳。
- 最后分组聚类。系统按关联强度把搭配分成极强、紧密、一般等层级,并生成搭配网络图,用节点大小和连线粗细展示核心词对的连接结构。
报告还会标记两个词谁在前、谁在后。这一点很重要:「研究」在「方法」前面和「方法」在「研究」前面,语义方向不同,不能混为一谈。
适用文档
舆情与新闻报道很适合用词语共现分析。当一批报道涉及同一事件或同一主体时,不同媒体的措辞差异往往体现在搭配结构上:消费者报道里「质量」和「投诉」共现,品牌通稿里「质量」和「认证」共现。搭配网络图可以把两套话语结构清晰分开。
学术文献与访谈记录适合。研究者在做文献综述或访谈编码时,经常需要判断几个概念之间是否存在语义关联。共现分析可以提供量化依据:共现次数高且三项指标都显著的词对,关联更可靠;只有一项指标偏高的词对,可能需要更多材料验证。
知识图谱与主题网络的前期准备适合。搭建知识图谱时,实体之间的关系需要从文本中提取。词语共现分析可以作为第一步筛选,把稳定可靠的词对挑出来,再做进一步的关系分类。
政策文本与行业报告适合。政策文件中「监管」和「合规」的搭配频率、行业报告中「增长」和「驱动」的搭配结构,可以反映文件的论述重点和话语倾向。
文本质量方面,文本越长、越完整,共现统计越稳定。很短的片段(几百字以内)会让共现次数偏低,三项指标容易失真。网页导航、脚注、重复模板和乱码会引入虚假共现,通常先清理正文再分析更稳。
语言方面,中文和英文都能处理,但需要先分词。中文分词质量直接影响共现结果,专有名词如果被拆开,会产生不存在的词对。正式分析前,可以先检查分词结果是否合理。
使用步骤
第一步:先明确你要回答的问题。舆情分析通常问「不同来源的搭配结构有什么差异」;访谈研究通常问「这几个概念之间有没有稳定的语义关联」;知识图谱准备通常问「哪些词对值得进一步做关系分类」。问题不同,后面看的指标和配置也不同。
第二步:设置窗口大小。窗口决定多远距离内的共现会被捕捉。2~5 词适合捕捉紧密搭配(如「数据分析」「深度学习」);8~15 词适合捕捉更松散的话题关联(如「气候变化」和「极端天气」在一句话里出现)。初次使用建议从 5 词开始,再根据结果调整。
第三步:选择共现词数。2 词共现最常见,适合找简单的词对关系。3 词和 4 词共现适合找更复杂的搭配模式,但数据量会更大,结果也需要更多材料支撑。
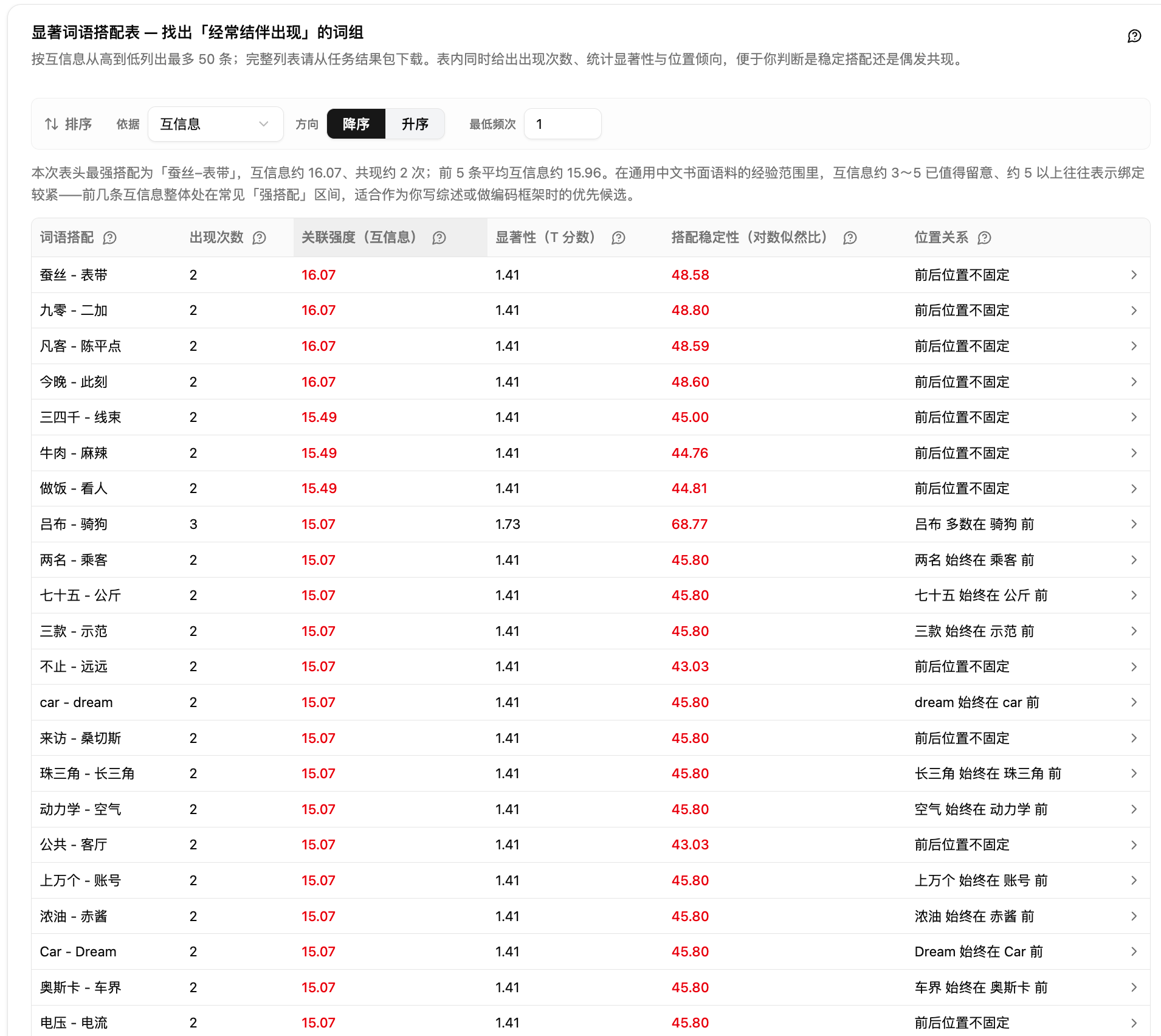
第四步:阅读词对搭配表。搭配表列出每组词对的共现次数、互信息值、T 值、对数似然比和前后位置关系。先按共现次数排序,看哪些词对出现最频繁;再按互信息或 T 值排序,看哪些搭配最稳定。
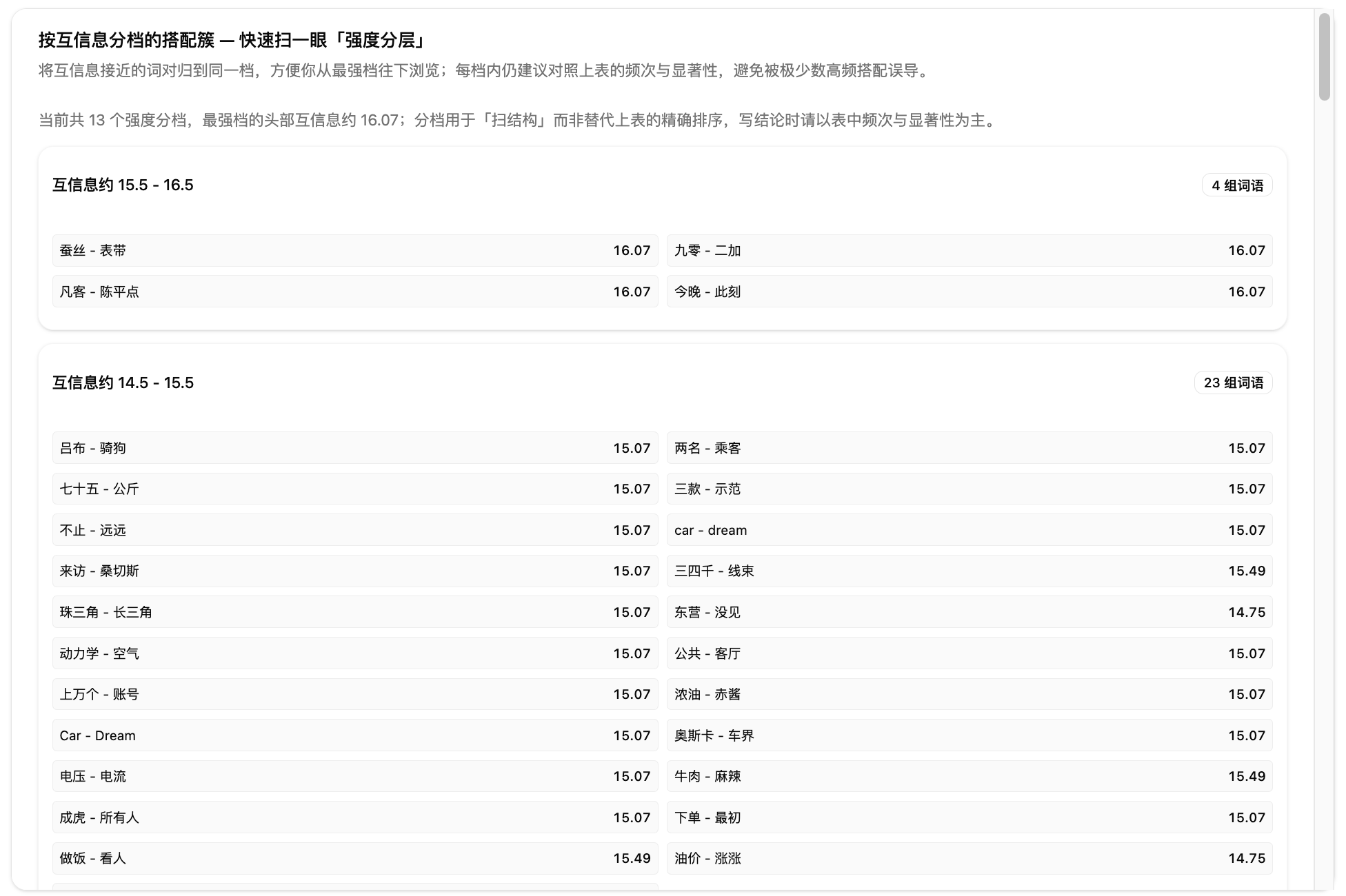
第五步:查看分组聚类。系统按关联强度把搭配分成极强、紧密、一般等层级。极强搭配通常是核心术语或固定表达,紧密搭配反映稳定的语义关联,一般搭配可能是偶然共现或需要更多材料验证。
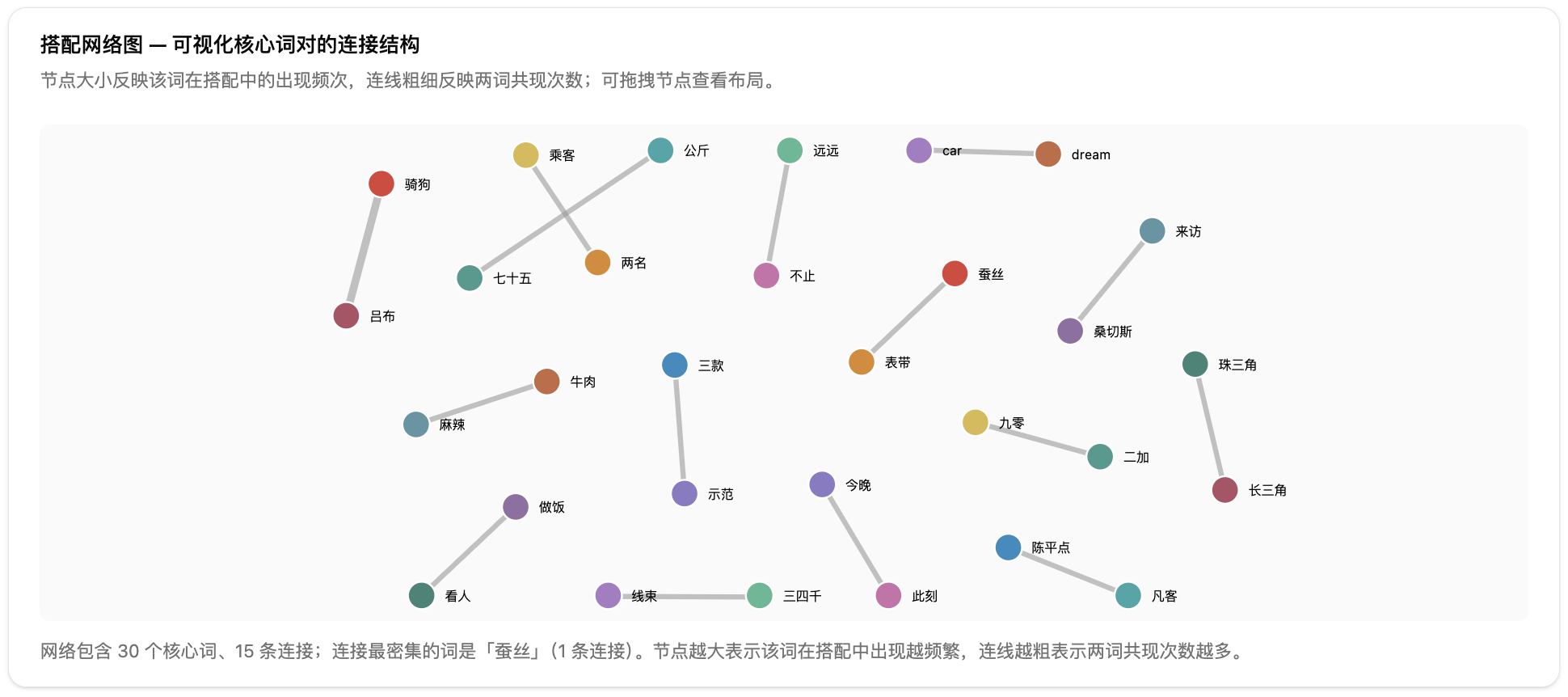
第六步:查看搭配网络图。网络图用节点大小表示共现频率,连线粗细表示关联强度。节点密集的区域通常是文本的核心话题,孤立节点可能是边缘概念或噪音。多文件对比时,可以分别生成网络图,比较不同来源的搭配结构差异。
参数解析与对比示例
可配置参数如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 窗口大小 | 共现扫描的左右词数范围,2~15 词 | 5 |
| 共现词数 | 每组搭配包含的词数,支持 2、3、4 词 | 2 |
| 最低共现次数 | 过滤掉出现次数过少的词对,减少噪音 | 3 |
| 排序方式 | 按共现次数、互信息、T 值或对数似然比排序 | 共现次数 |
四组典型配置供参考。
- 舆情话语分析。窗口设 5~8,共现词数 2,最低共现次数 3。重点看搭配网络图和跨文件对比,比较不同来源的搭配结构差异。
- 访谈概念关联。窗口设 3~5,共现词数 2,最低共现次数 2。重点看互信息和 T 值,筛选出统计显著的词对。
- 知识图谱准备。窗口设 5,共现词数 2,最低共现次数 5。重点看分组聚类中的极强和紧密搭配,作为实体关系的候选。
- 复杂搭配模式。窗口设 5~8,共现词数 3 或 4,最低共现次数 2。适合找多词搭配结构,但需要更大语料量支撑。
三种指标的含义需要特别注意。互信息衡量共现频率相对随机水平的偏离程度,值越高说明搭配越不可能是碰巧;T 值衡量搭配的统计显著性,受共现次数影响较大,高频词对的 T 值更容易偏高;对数似然比衡量搭配的稳定性,对低频词对更敏感。三项指标综合判断比单看一个更稳,尤其在共现次数不多时,互信息和对数似然比可以补充 T 值的不足。
案例分析
案例一:舆情话语结构对比。
背景:一个舆情分析团队需要梳理某品牌在 30 篇新闻报道中的话语口径。消费者投诉类报道和品牌官方通稿都在讨论「质量」,但读感不同。
配置:窗口设 5,共现词数 2,最低共现次数 3。
结果:搭配表显示消费者报道中「质量」和「投诉」「问题」频繁共现,互信息值偏高;品牌通稿中「质量」更多和「认证」「标准」搭配。搭配网络图把两套话语结构清晰分开,两个网络几乎不重叠。
结论:消费者关注的是质量问题本身,品牌在强调合规背书。团队据此判断两套口径差异明显,舆情应对需要分别制定策略。
案例二:访谈概念关联验证。
背景:一个社会学研究者分析 20 篇访谈记录,想确认「社区」「参与」「信任」三个概念之间是否存在稳定的语义关联,用于指导编码方案。
配置:窗口设 3,共现词数 2,最低共现次数 2。
结果:搭配表显示「社区」和「参与」共现次数高、T 值显著,属于紧密搭配;「社区」和「信任」共现次数中等,但对数似然比偏低,搭配不够稳定;「参与」和「信任」共现很少,三项指标都不显著。
结论:「社区参与」可以作为核心类目,「社区信任」需要更多材料验证,不能把三者默认为等价关联。研究者据此调整了编码方案,优先编码「社区参与」相关内容。
案例三:政策文本论述重点提取。
背景:一个研究团队分析 10 份行业监管政策文件,想了解不同文件的论述重点和话语倾向。
配置:窗口设 8,共现词数 2,最低共现次数 5。
结果:分组聚类显示「监管」和「合规」「风险」构成极强搭配群,「创新」和「发展」「技术」构成另一个搭配群。跨文件对比显示早期文件以「监管」搭配群为主,近期文件「创新」搭配群的共现强度明显上升。
结论:政策话语从强调监管合规逐步转向鼓励创新发展。团队据此在研究报告中增加了政策演变的时间线分析。
类似功能对比
词语共现分析、词语搭配强度分析、关键词抽取都和词语关系有关,但关注点不同。
| 对比维度 | 词语共现分析 | 词语搭配强度分析 | 关键词抽取 |
|---|---|---|---|
| 做什么 | 扫描窗口内词对的共现关系,用三种指标判断搭配可靠性 | 衡量两个特定词之间的搭配强度 | 从文本中提取最重要的词 |
| 关注点 | 词对之间的共现结构 | 特定词对的搭配程度 | 单个词的重要性 |
| 典型问题 | 哪些词经常一起出现、搭配是否可靠 | 这两个词搭配紧不紧 | 这篇文章的关键词是什么 |
| 输出 | 词对搭配表、分组聚类、搭配网络图 | 搭配强度值和显著性 | 关键词列表和权重 |
| 典型场景 | 舆情话语分析、概念关联验证、知识图谱准备 | 特定词对的搭配程度判断 | 文章主题提取、标签生成 |
如果你想看「哪些词经常一起出现」,用词语共现分析。如果你已经有两个词想确认「它们搭不搭配」,用词语搭配强度分析。如果你想知道「这篇文章讲什么」,用关键词抽取。三者可以连续使用:先用关键词抽取找到核心词,再用共现分析看搭配结构,最后对重点词对用搭配强度分析做精细判断。