关键词抽取做的事情是:从文本中自动找出最重要的词或短语,按权重排序。
系统同时跑两种算法,各有侧重。
- TF-IDF 看的是"稀有但重要"。一个词在当前文本里出现得多,在其他文本里出现得少,它的 TF-IDF 权重就高。简单说,这个词对你这篇文档特别有代表性。
- TextRank 看的是"上下文互相支撑"。它把文本里的词当作图里的节点,两个词经常一起出现就连一条边,最终通过图排序算出哪些词和更多词产生共现关系。和更多词关联紧密的词权重更高。
两种算法跑完后,系统自动做三件事:一是统计共有关键词和各自独有词,二是计算 Spearman 排名相关系数衡量两种方法的一致性,三是把差值最大的词标出来。相关系数高说明两种方法认同度高,结果可信;差值大的词值得重点关注,可能是某种算法捕捉到的独特信号。
报告页还包含词云、权重柱状图、跨文件对比表、噪声词过滤面板、密度诊断和主题聚类等多个分析模块,帮你从不同角度看关键词。
适用文档
目前支持两种输入格式。
- TXT 文件。按全文处理,一个文件算一个整体。编码建议用 UTF-8,其他编码出现乱码可以先转一下。
- CSV 文件。按行处理,每一行独立提取关键词。自动识别文本列,非文本列原样保留。需要带表头。
中文和英文都支持,系统会自动识别语言。中英混排也可以处理,中文部分和英文部分分别用对应的分词策略。
适用情景
- 竞品内容分析。把竞品文章批量上传,提取关键词后对比共享词和独有词,找到差异化关键词做内容策略。
- 学术文献综述。从论文摘要或全文中提取学科术语,用跨文件对比功能识别高频共现术语和各篇独有术语。
- 用户评论挖掘。从电商评论、问卷开放题中提取功能点和痛点关键词,密度诊断帮你判断哪些词被反复提及。
- 政策文本分析。从政策文件中提炼核心概念和关键表述,主题聚类会把语义相近的关键词自动分组。
- SEO 内容优化。提取目标页面的关键词权重分布,检查关键词密度是否在合理范围,避免堆砌或不足。
使用步骤
第一步:上传文件。你可以上传一个或多个 TXT 或 CSV 文件,系统逐个处理。
第二步:配置参数。上传后页面显示参数配置区域,默认提取 20 个关键词。你可以调整提取数量、上传自定义词典和停用词表、开启词性筛选等,具体含义在下一节展开。

第三步:查看报告。提交后系统自动处理,完成后跳转到报告页。报告从上到下依次是:数据解读卡片、TF-IDF 结果区、TextRank 结果区、两种方法的对比区。
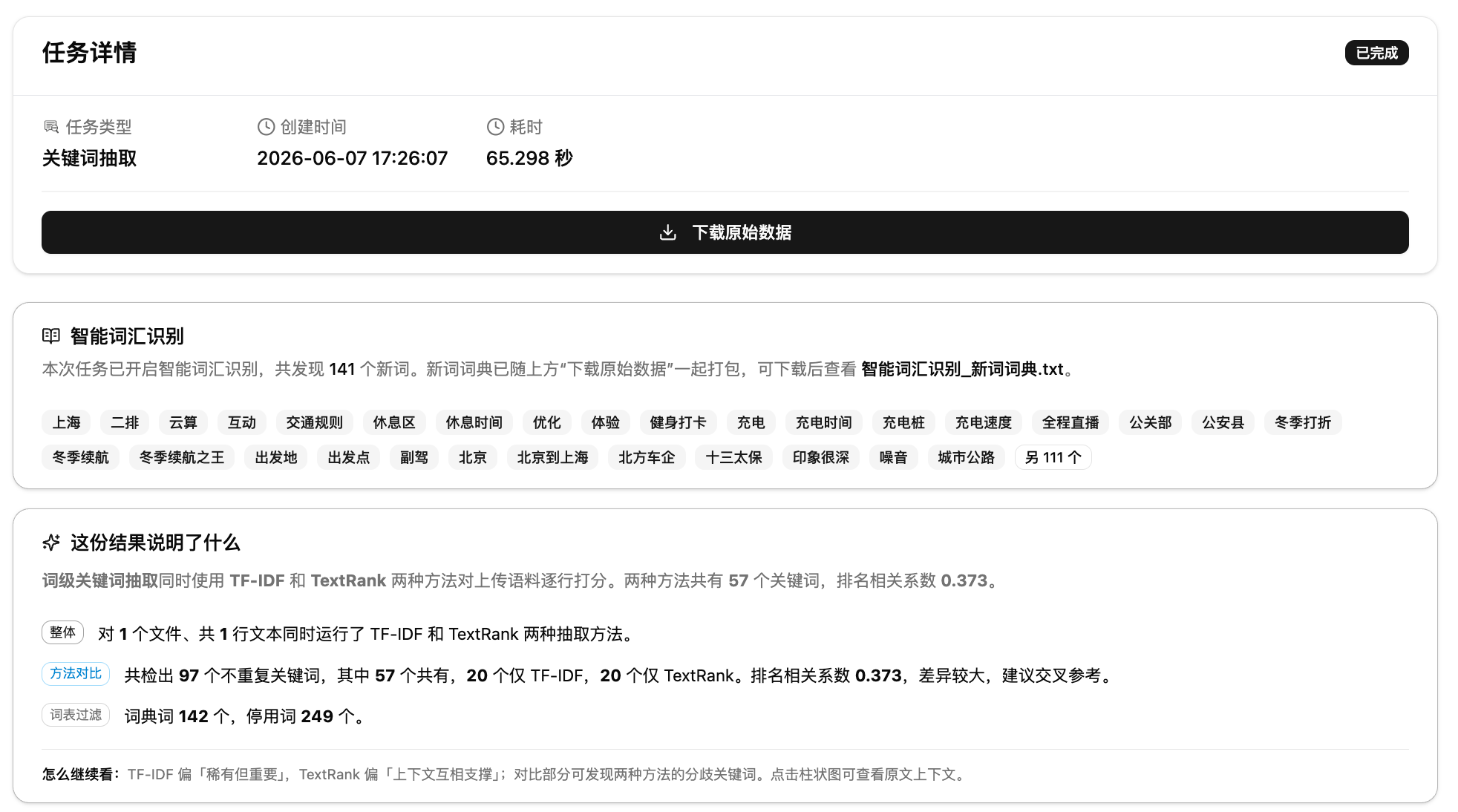

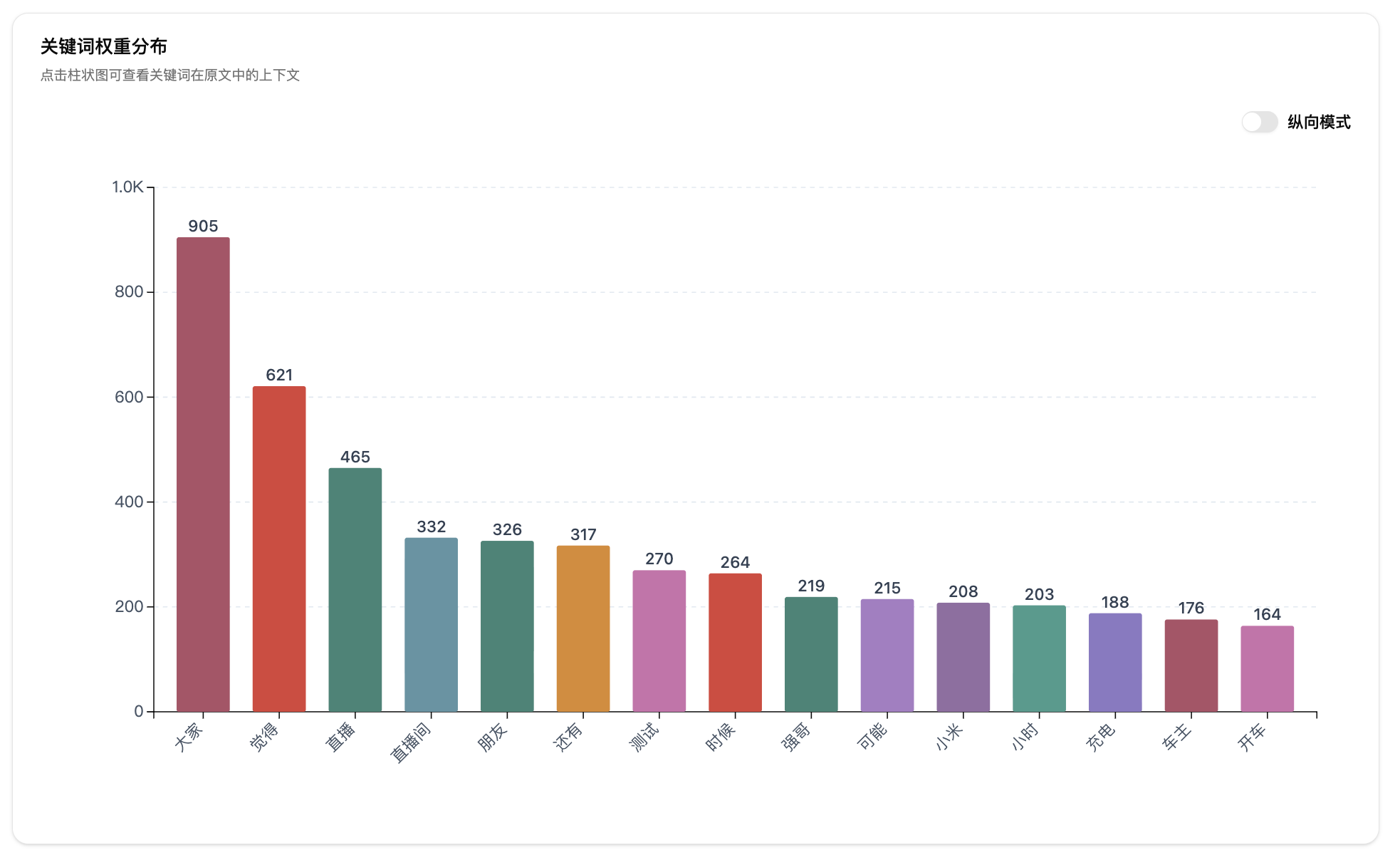
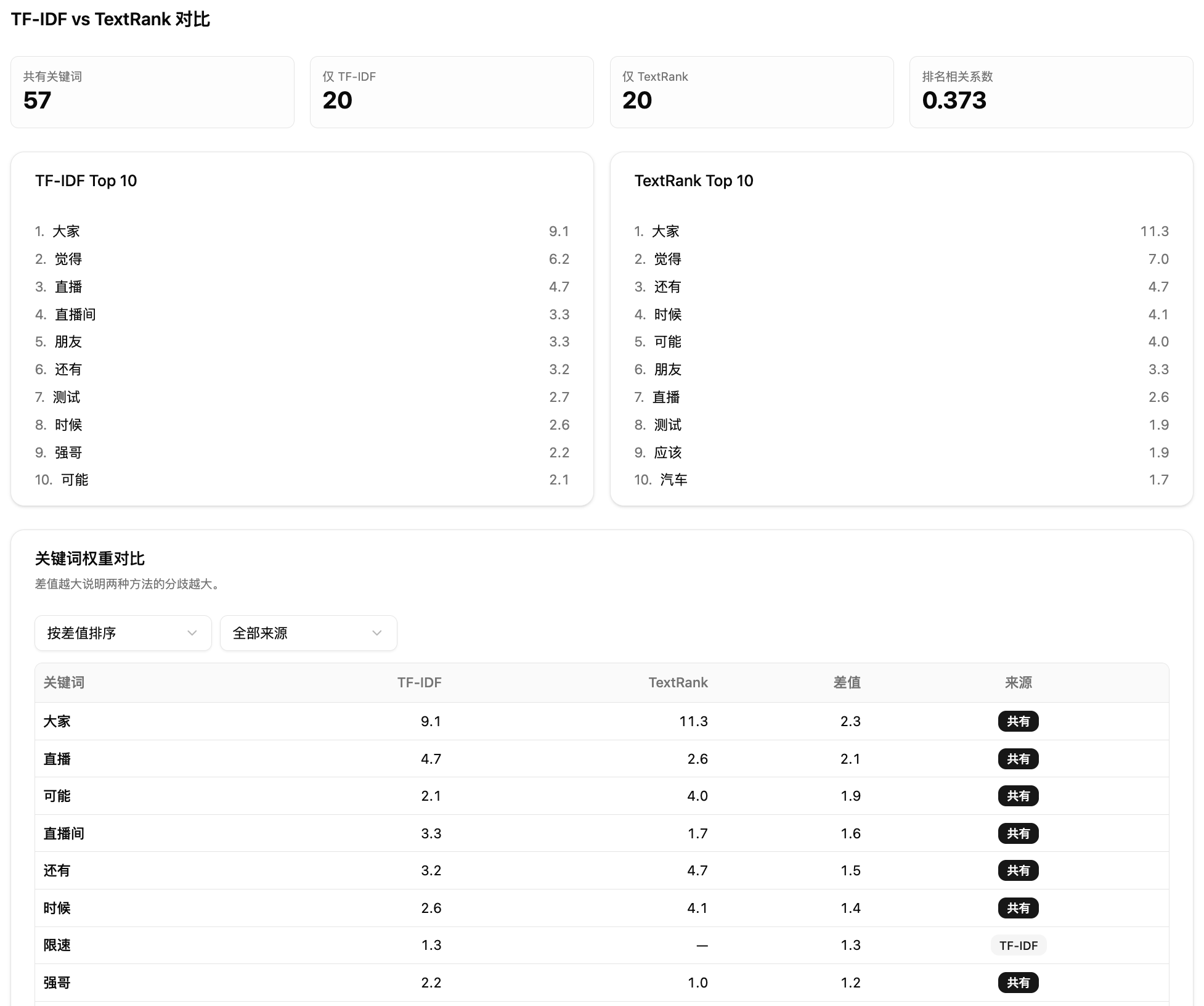
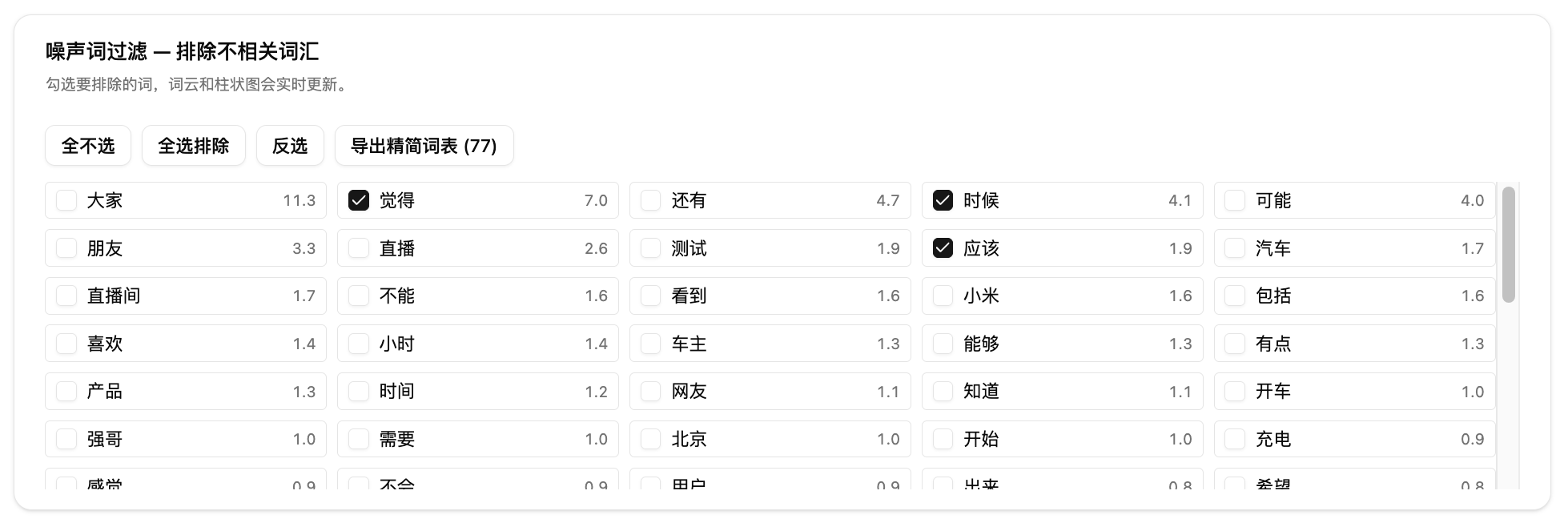
第四步:筛选与导出。在噪声词过滤面板勾选要排除的词,词云和柱状图会实时更新。点击柱状图可以查看关键词在原文中的上下文片段。筛选完成后可以导出精简词表。
第五步:下载结果。点击下载拿到每种方法的 CSV 结果文件,包含关键词、权重和总分。
参数解析与对比示例
可配置参数如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 提取数量 | 每种方法提取的关键词数量,范围 5-100 | 20 |
| 自定义词典 | 上传词典文件,每行一个词,帮助分词工具识别专有名词和领域术语 | 未上传 |
| 自定义停用词表 | 上传停用词文件,每行一个词,提取前自动过滤这些词 | 未上传 |
| 词性筛选 | 开启后排除指定词性类别,默认保留名词、动词、形容词等实义词 | 关闭 |
| 排除词性 | 勾选要排除的词性类别(需先开启词性筛选) | 无 |
| 语言 | 文本主要语言,影响分词策略 | 中文 |
| 智能新词发现 | 自动发现语料中的新词,补充分词词典 | 关闭 |
三组典型配置供参考。
- 快速提取。保持默认配置,提取数量 20,其他参数不动。适合初次使用,快速看结果。处理速度快。
- 术语强化提取。上传自定义词典,包含领域专业术语。适合医学、法律、IT 等专业文档,能减少术语被错误切分的情况。提取数量建议设为 30-50。
- 精细筛选提取。开启词性筛选,排除介词、连词、助词等功能词,同时上传自定义停用词表。适合需要纯净实义关键词的场景。结果更聚焦,但可能漏掉一些有分析价值的虚词搭配。
提取数量设得越多,覆盖越全但噪声也越多。一般来说 20-30 适合快速浏览,50 以上适合深度分析。
案例分析
案例一:竞品文章关键词对比。
背景:某内容团队收集了 5 篇竞品公众号文章,想找出差异化关键词做选题参考。
配置:提取数量 30,其他参数默认。
结果:5 篇文件共检出 87 个不重复关键词。TF-IDF 和 TextRank 共有关键词 23 个,排名相关系数处于中等一致性水平。跨文件对比表显示共享词 12 个(如"用户""内容""平台"),各篇独有词 5-8 个不等。团队重点关注 TextRank 独有的关键词,发现"留存""转化""裂变"这类运营词在 TextRank 中权重更高,说明它们在原文中和其他词的共现关系更紧密。
结论:两种方法的分歧关键词往往是价值所在。TF-IDF 捕捉稀有但有代表性的词,TextRank 捕捉上下文关联紧密的词,交叉参考后选题方向更全面。
案例二:用户评论痛点挖掘。
背景:某产品团队收集了 200 条用户评论(CSV 格式,每行一条评论),想了解用户最关心的功能点和痛点。
配置:提取数量 50,开启智能新词发现,自定义停用词表包含"一个""这个""那个"等口语化填充词。
结果:每行评论独立提取关键词后汇总。密度诊断显示"卡顿""闪退""加载"三个词的密度超过 5%,属于高频堆砌词,反映了用户最集中的痛点。主题聚类把关键词分成 5 组:性能相关(卡顿、加载、闪退)、功能相关(搜索、筛选、收藏)、界面相关(布局、字体、颜色)、价格相关(优惠、折扣、会员)、服务相关(客服、退款、投诉)。
结论:密度诊断帮你快速定位高频问题词,主题聚类帮你把散乱的关键词归类成可操作的问题域。
类似功能对比
关键词抽取和高频词提取、词性标注都跟"词"有关,但做的事情不一样。
| 对比维度 | 关键词抽取 | 高频词提取 | 词性标注 |
|---|---|---|---|
| 做什么 | 用算法提取最重要的词 | 按出现次数统计最常见的词 | 给每个词标语法类别 |
| 关注点 | 词的重要程度和代表性 | 词的出现频率 | 语法结构和词性分布 |
| 考虑上下文 | 是(TextRank 基于共现关系) | 否(纯频次统计) | 否(只关注词性) |
| 输出 | 关键词列表 + 权重排序 | 词频表 + 频次排序 | 词性分布 + 转移矩阵 |
| 典型场景 | 主题分析、标签生成、SEO | 词频统计、语料概览 | 语法研究、风格分析 |
高频词提取只看出现次数,"的""了""是"这类虚词如果没过滤掉会排在最前面。关键词抽取通过 TF-IDF 和 TextRank 算法过滤掉了这类常见词,结果更接近文本的核心主题。词性标注可以和关键词抽取组合使用:先标注词性,再按名词、动词等类别筛选后做关键词抽取,结果更聚焦。