为什么需要「先体检再分析」
文本基础概览回答:这篇东西有多大、句长节奏如何、字符构成和标点习惯怎样、词汇是否过于单调——适合稿费核对、多稿对比、教学材料检查。
NLP 任务适用性体检回答:这份文件是否「干净到能进流水线」:重复是否模板化、有效字符是否足够、熵与结构是否异常,并给出对聚类、LDA、BERTopic、NER、情感、摘要六类输入的合格/不合格判断。
两套视角不重叠:前者偏可读性与规模,后者偏技术门槛。全程纯算法统计扫描,因此速度快、可复现;代价是对古文、口语、对话、代码、表格等非常规格式可能偏严,需要结合业务语境解读。
「文本质量评估」与相关工具怎么选
| 需求 | 用「文本质量评估」 | 更适合其他工具/说明 |
|---|---|---|
| 跑分析前快速筛掉空文件、乱码、极端模板 | ✅ | — |
| 看 TTR / MTLD / HD-D 三项概览 + 句长分布 | ✅ | 报告内嵌 |
| 做学术级词汇多样性全矩阵、滑窗、多文件深度对比 | 部分 | 「词汇等级评估」「文体风格指纹」 |
| 看句子级可读性分数 | 否 | 「文本可读性」「信息价值评估」 |
| 统一中文标点/繁简/全半角 | 否 | 「中文文本规范化」 |
| 找「哪几份文档内容相似」 | 否 | 「文本去重雷达」 |
功能入口:快速直达→
报告里两大板块分别看什么
区块一:文本基础概览
面向写作、翻译、编辑、教学,主要包括:
- 规模:总字数、净字数(去空白)、词数(英文为词、中文为字,便于混排比较)、句数、段数、唯一词数——为分词、向量化等下游任务提供体量基线,也是判断语料是否足以支撑统计分析或模型训练的第一道参考。
- 句长:短句(≤15 词)与长句(≥40 词)占比、P50/P90、句长直方图(等距分箱,最多 10 箱);切句规则含
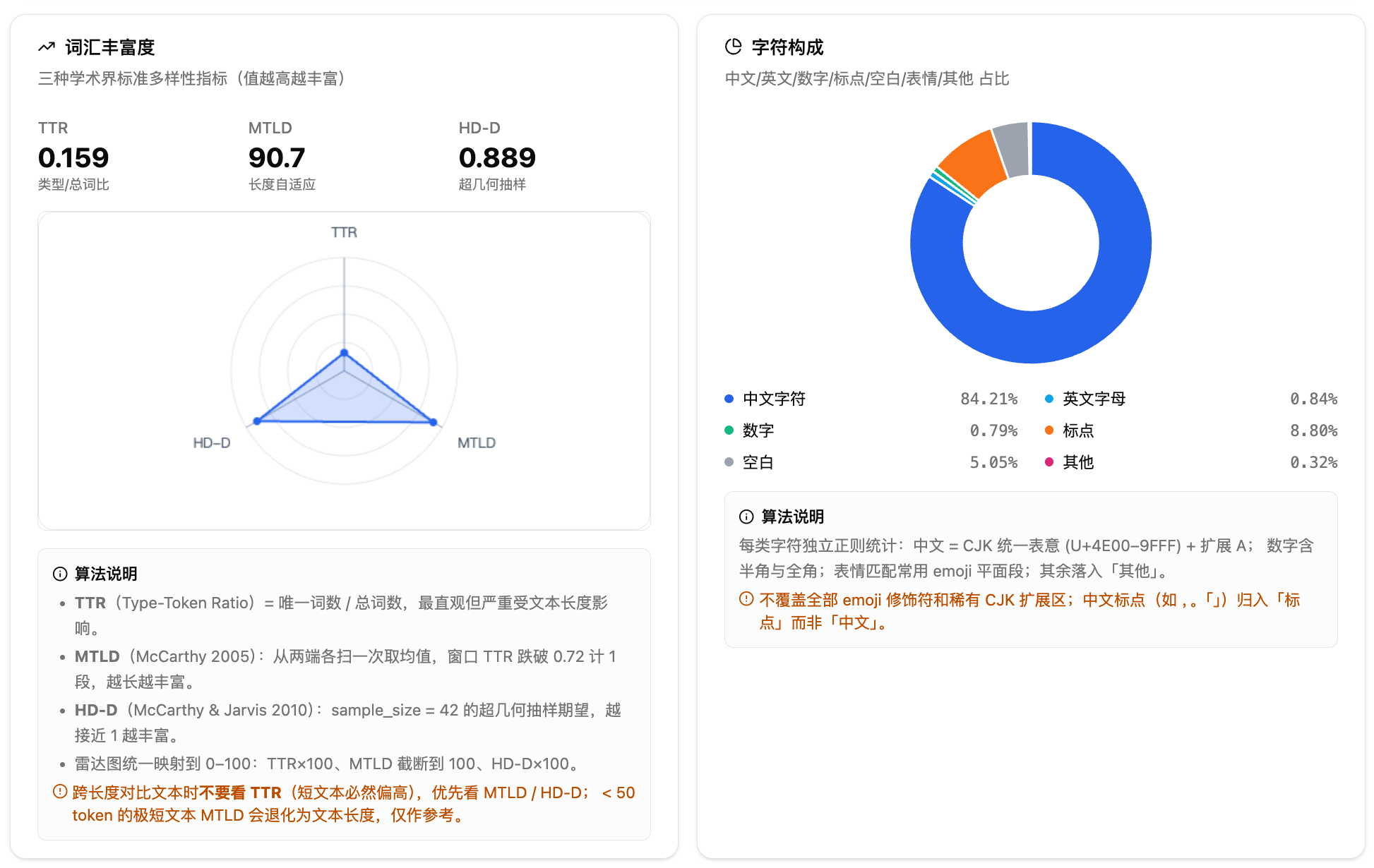
。!?!?.…等——句长分布直接影响切句、依存解析与摘要任务的稳定性,过长句子往往是解析错误和语义边界混乱的高发区。 - 词汇丰富度三件套:TTR(Type-Token Ratio)、MTLD、HD-D,雷达图将三者映射到 0–100 可比尺度,可作为风格分类、作者识别、机器生成文本检测等任务的特征信号(MTLD 与 HD-D 比 TTR 更不受文本长度干扰)。
- 字符构成饼图:中文、英文、数字、标点、空白、表情、其他——字符分布决定了分词器的选型与编码策略,中英混排或表情占比偏高的文本往往需要专门的 tokenizer 才能避免切分异常。
- 全角/半角标点计数:作排版习惯参考(代码、URL 多会抬高半角),也用于规范化预处理:全半角不统一会让正则匹配、关键词检索和句子边界识别在同一份语料里出现"看似相同却命中不到"的情况。
读数要点:跨不同长度文件对比时,不要直接比 TTR(短文本往往虚高);优先看 MTLD 与 HD-D。极短文本(例如 < 50 token)上 MTLD 会退化,仅作参考。
区块二:NLP 任务适用性体检
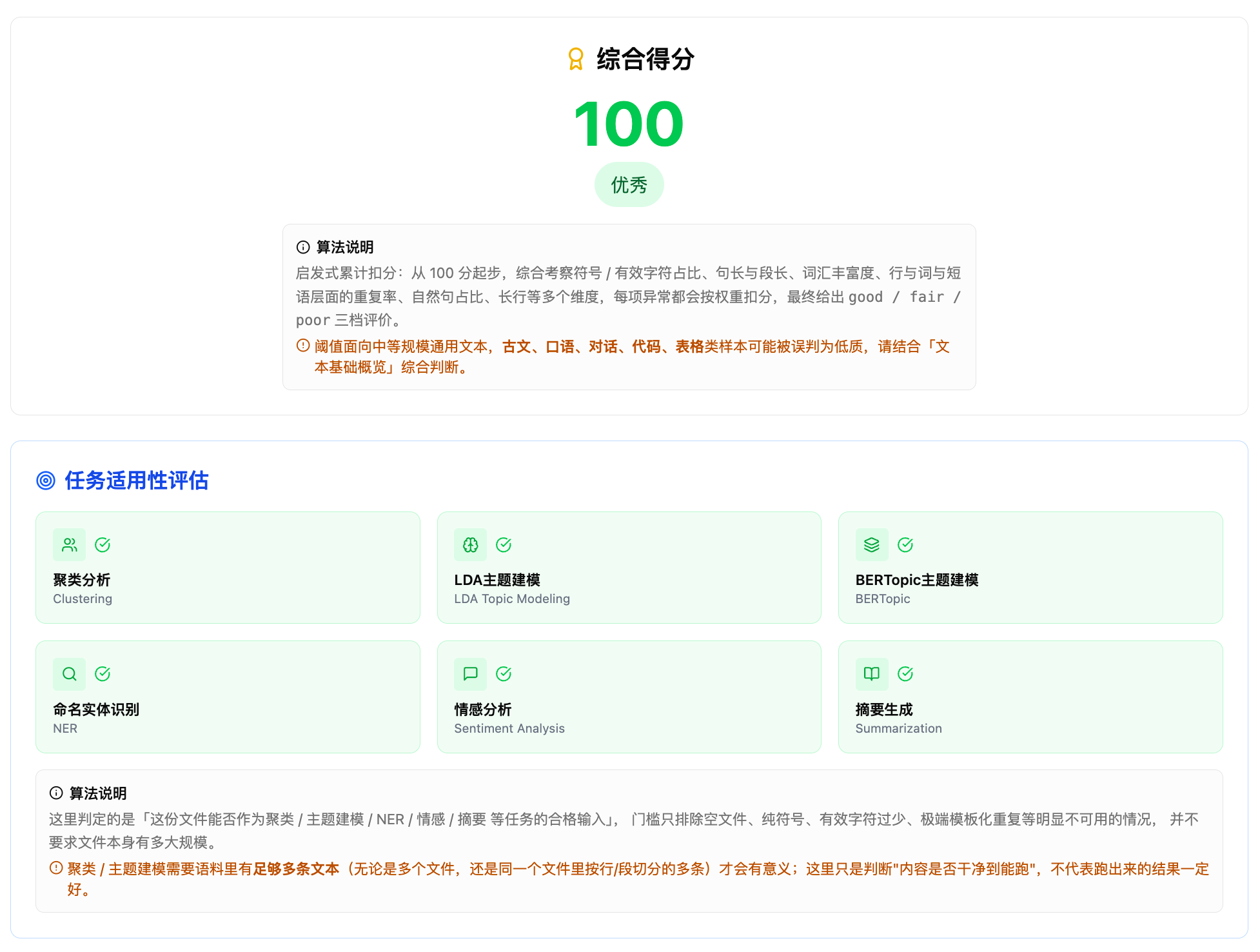
从原文一遍扫描,指标归入六组维度(界面上有「基础统计 / 重复性 / 文本组成 / 词汇质量 / 结构特征 / 信息密度」等说明),并得出:
- 0–100 综合分与
good/fair/poor三档(启发式从 100 分起按符号占比、句段长度、重复率、自然句比例等累计扣分) - 六张任务卡:是否适合聚类、LDA、BERTopic、命名实体识别(NER)、情感分析、自动摘要——表示「能否作为合格输入」,不预测效果多好
重复性在三个粒度:行(去重行比)、词(与 1−TTR 相关)、3-gram 短语重复。高重复常见于模板、爬虫块、逐字复述;但词典体、法条、年报等合理高重复不一定代表低质。
平台操作:从上传到读报告
工具页仅支持 **.txt 纯文本**上传(界面配置为单文件最大约 5 MB、一次最多约 10 个文件,以当前线上界面为准)。无独立参数面板:上传即算。
第 1 步:准备语料
- 将待检内容存为 UTF-8 的
.txt;多文档建议一文件一篇或按你们下游任务习惯的粒度拆分,便于多文件对比表对齐 - 若原文在 Word/PDF,请先导出或复制为纯文本,避免带大量不可见控制符
第 2 步:在工具页上传并提交
- 在「文本质量评估」页拖入或选择文件,确认列表与数量
- 点击运行/提交,等待任务完成后在任务详情中打开报告
第 3 步:阅读报告
- 多文件时:先用顶部文件切换看单文件全文指标,再滚到「多文件对比」表横向对规模、TTR/MTLD/HD-D、平均句长
- 单文件时:从「文本基础概览」扫一眼规模与句长,再下看 NLP 综合分与六类任务卡;红色任务卡表示当前统计口径下不建议把该文件当作该类任务的输入
- 需要下载表格式汇总时:任务侧会产出 CSV(具体列以当次结果为准),便于和团队共享
⚠️ 顺序与预期管理
- 先清洗再体检或先体检再决定要不要清洗都可以;若未做去 HTML/去重复页眉页脚,重复率与综合分可能偏低,这是数据形态问题,不是工具坏了
- 聚类/主题类任务要有效,通常还需要语料里有多条可分的文本;工具只表示单文件是否干净可喂,不保证主题有多少个、聚类多漂亮
| 你看到的红叉 | 常见真实含义 |
|---|---|
| 某任务「不适合」 | 长度过短、有效字符比过低、或综合质量档为 poor 等门槛触发 |
| 综合分低 | 可能混有大量符号、极端重复、句段结构异常、长行粘贴等,对照报告分组逐项看 |
常见问题
Q: 综合分 good 是否代表论文一定能发、模型一定效果好?
不代表。分数与任务卡都是统计启发式,衡量「像不像正常可用于 NLP 的通用中文/英文语料」。效果仍取决于具体任务、标注与模型。
Q: 为什么 BERTopic 显示适合、聚类却显示不适合?
各任务在实现里门槛不同(例如对字符量、去重、有效字符比例的最低要求不同)。以报告内实时结果为准,不要跨任务强行对齐成同一标准。
Q: TTR 在 A 文件比 B 文件高,能否说明 A 用词更丰富?
若两段文本长度差很多,不能直接下结论。更稳妥的是比较 MTLD、HD-D,或控制长度后再比。
Q: 口语对话、微博短帖为什么分数往往不好看?
切句、句长、自然句比例等规则面向成段书面语;对话、大量省略与碎片句会被判得更「难伺候」。此时请优先相信业务需求,并参考「文本基础概览」里你们真正关心的规模与节奏指标。
Q: 和「词汇多样性」工具有什么关系?
本工具的 NLP 部分已带 TTR / MTLD / HD-D 三项概览;「词汇多样性」在站内是同方向的专项加深(完整指标矩阵、学术引用、更多对比能力),二选一或组合使用即可。