文体风格指纹做的事情是:把文本里的写作习惯变成一组可比较的风格特征。它不判断文章好坏,也不替你做作者鉴定,而是把读感拆开,告诉你差异来自哪些维度。
处理过程可以理解成四步。
- 先看句子节奏。平均句长、最长句、最短句、句长波动会显示文章是不是节奏不稳。作文里常见的「散」,很多时候不是观点不存在,而是句子一会儿很短、一会儿很长,读者很难跟住。
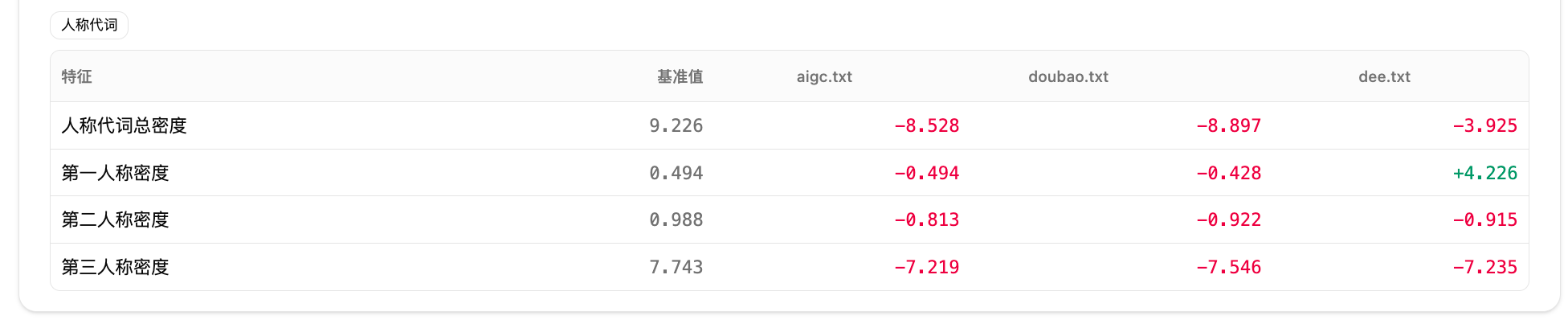
- 再看表达口吻。疑问句、感叹句、否定句、被动线索和人称代词会影响语气。第一人称高,文章更主观;第二人称高,文章可能更像教程或劝说;第三人称多,叙事感更强。
- 接着看词汇和词性。虚词、实词、连词、名词、动词、形容词等比例能反映信息密度和表达方式。名词密集通常信息量大,形容词偏多则修饰感更强。
- 最后看标点习惯。逗号、问号、感叹号、分号、引号、括号、破折号、省略号的密度,会影响停顿、情绪和解释结构。
报告的价值在于把「感觉」变成「线索」。你仍然需要回到原文判断,但修改方向会更清楚。
适用文档
改稿前后对照很适合用文体风格指纹。原稿、二改稿、终稿之间的主题通常相同,差异主要体现在表达方式上。风格指纹能看到终稿是否真的变得更紧凑,还是只是替换了个别词语。
多来源稿件也适合。活动通稿、品牌文章、说明材料如果来自不同作者,常见问题不是事实不一致,而是有的像公告、有的像教程、有的像口语分享。风格雷达和异常维度提示可以帮助定位哪几篇需要统一语气。
作者风格研究适合。当研究者需要比较几篇文本的写作习惯是否接近时,风格指纹可以提供可量化的特征向量。配合逐特征表和风格雷达,可以更细致地比较句长、标点和代词使用习惯。它只能提供统计线索,不能作为作者身份判断依据。
翻译风格评估也适合。译文和参照文本之间如果主题相同但读感不同,通常是因为句长结构、词汇密度或标点习惯发生了变化。风格指纹可以帮助定位这些变化。
写作诊断适合。老师或编辑判断一篇文章「写得散」「不够集中」时,风格指纹可以把模糊读感拆成具体指标,例如句长波动大、标点密度高、第一人称过多。
文本质量方面,正文越完整,指标越稳定。很短的片段会让标点、代词和句长指标被少数句子放大。网页导航、脚注、重复模板、乱码和表格符号会干扰标点密度和词汇结构,通常先清理正文再分析更稳。
语言方面,中文和英文都能处理,但同一篇里中英混排较多时,部分指标会受语言规则影响。正式比较时,尽量让材料类型一致,例如都用作文、都用通稿、都用同一篇文章的不同修改版本。
使用步骤
第一步:先明确你要回答的问题。改稿对照通常问「修改到底改变了什么」;稿件统一通常问「哪几篇风格偏离」;作者研究通常问「这几篇写作习惯是否接近」;写作诊断通常问「这篇文章的问题出在哪里」。问题不同,后面看的指标也不同。
第二步:选择关注维度。想看结构和节奏,重点保留句子层;想看语气,重点看人称代词和疑问感叹比例;想看表达是否累赘,重点看标点密度、虚词比例和句长波动。
第三步:阅读顶部解读。顶部解读会说明本次分析覆盖了多少篇文本、多少个风格维度,以及相似和不相似的判定阈值。这里适合先建立整体判断,不急着看细表。

第四步:看风格雷达。雷达图适合快速比较轮廓。某篇文章如果在句长、标点或代词相关角点明显外扩,就说明它在这些维度上更突出。
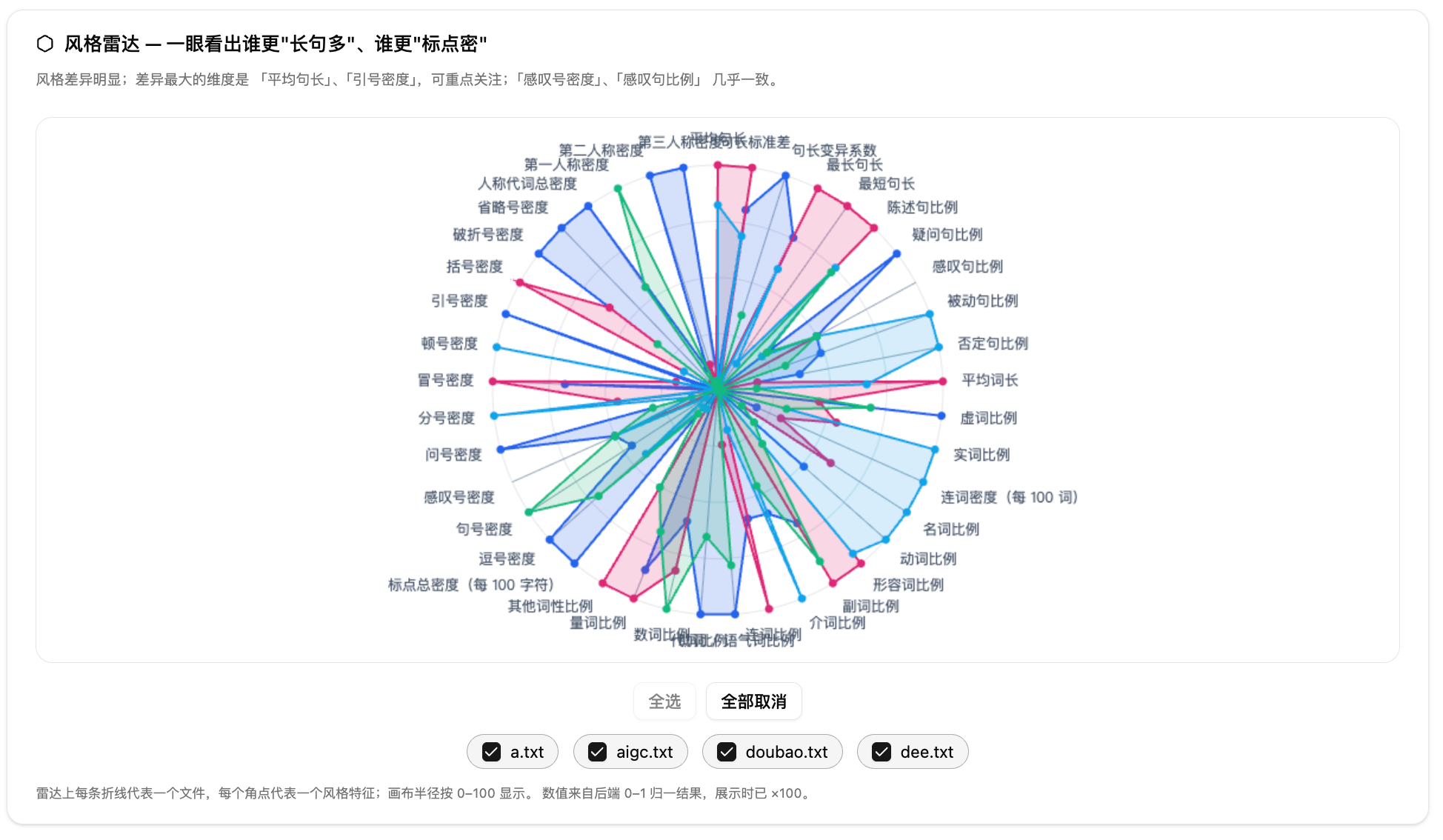
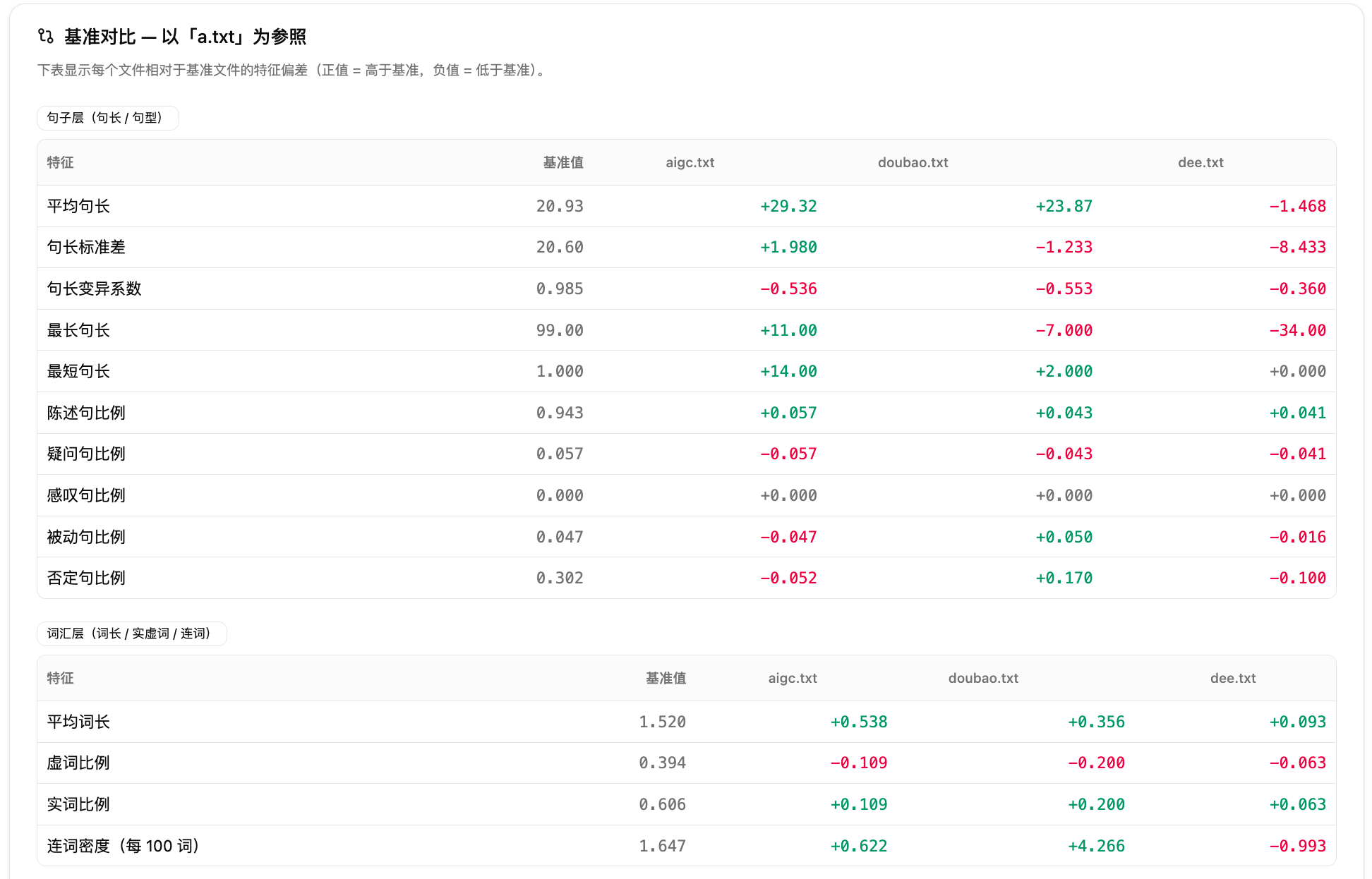
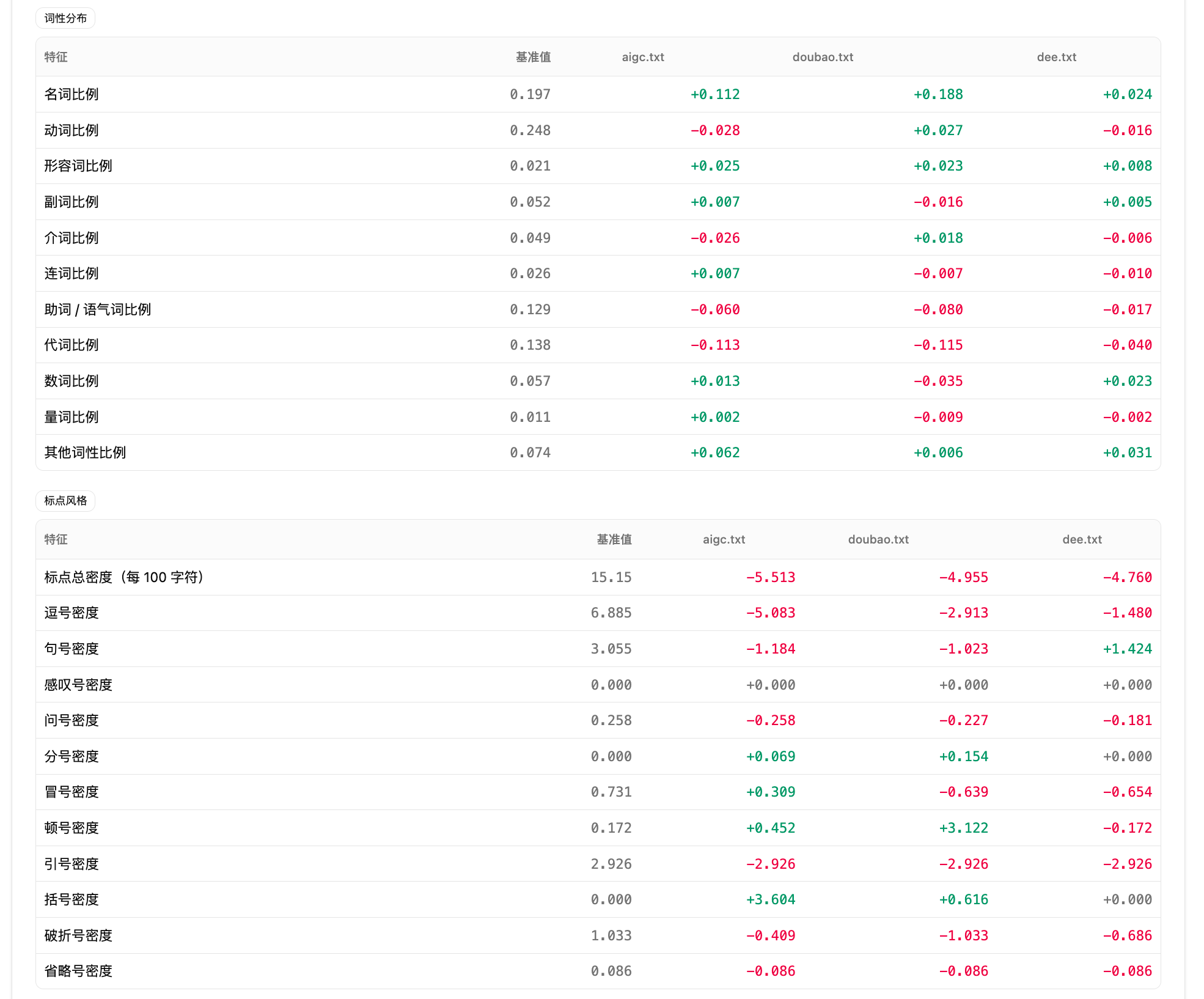
第五步:查看基准对比。如果选择了基准文件,报告会显示其他文件相对基准的偏差。不设置基准时,偏差参照批次均值。基准对比适合改稿前后对照,直接看终稿相对原稿在哪些维度收敛或放大。
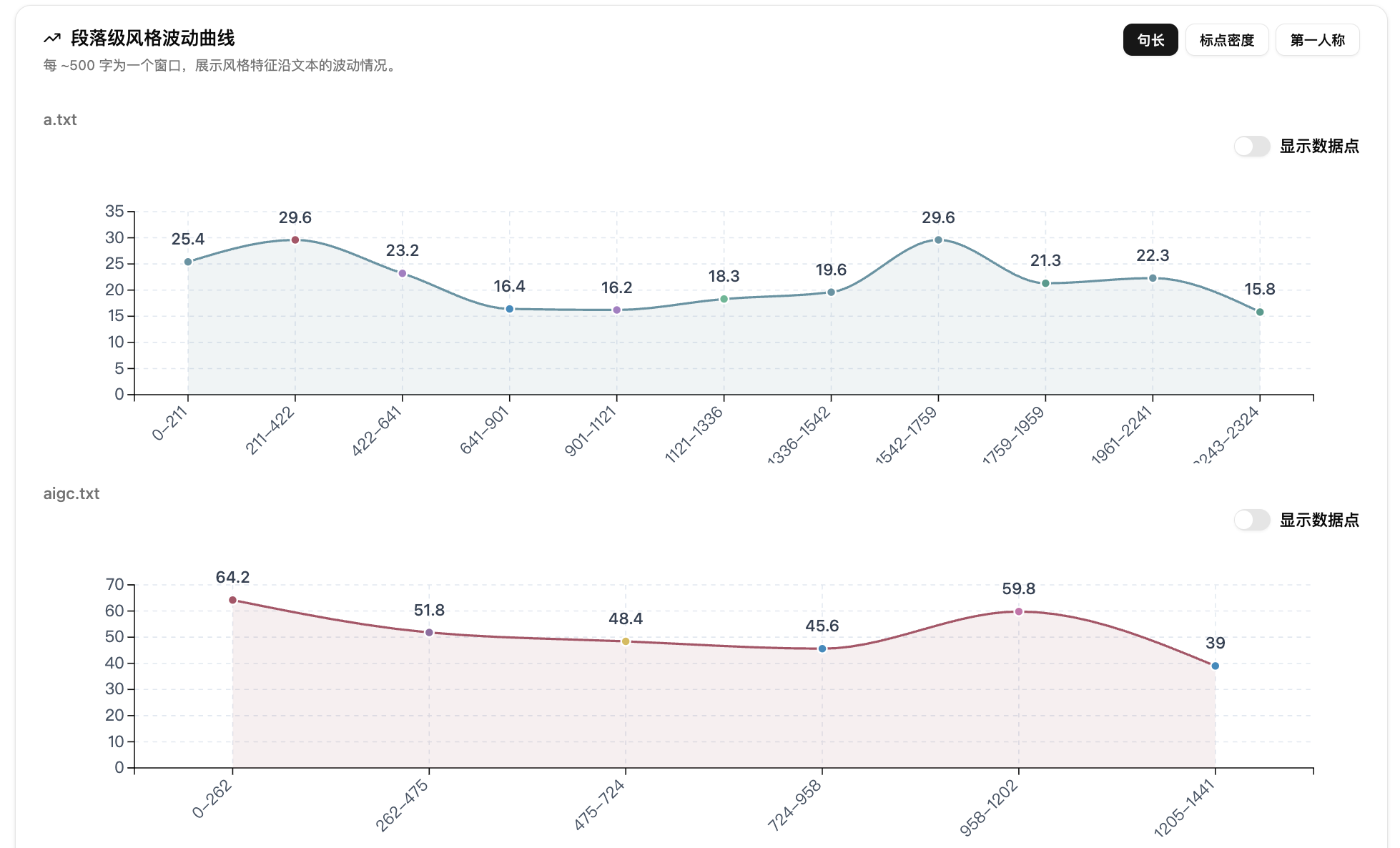
第六步:查看段落级风格波动曲线。开启智能分段后,报告会展示文本内部的风格变化,可在句长、标点密度、第一人称之间切换。它适合定位长文中节奏突然变密、语气突然变主观的段落。
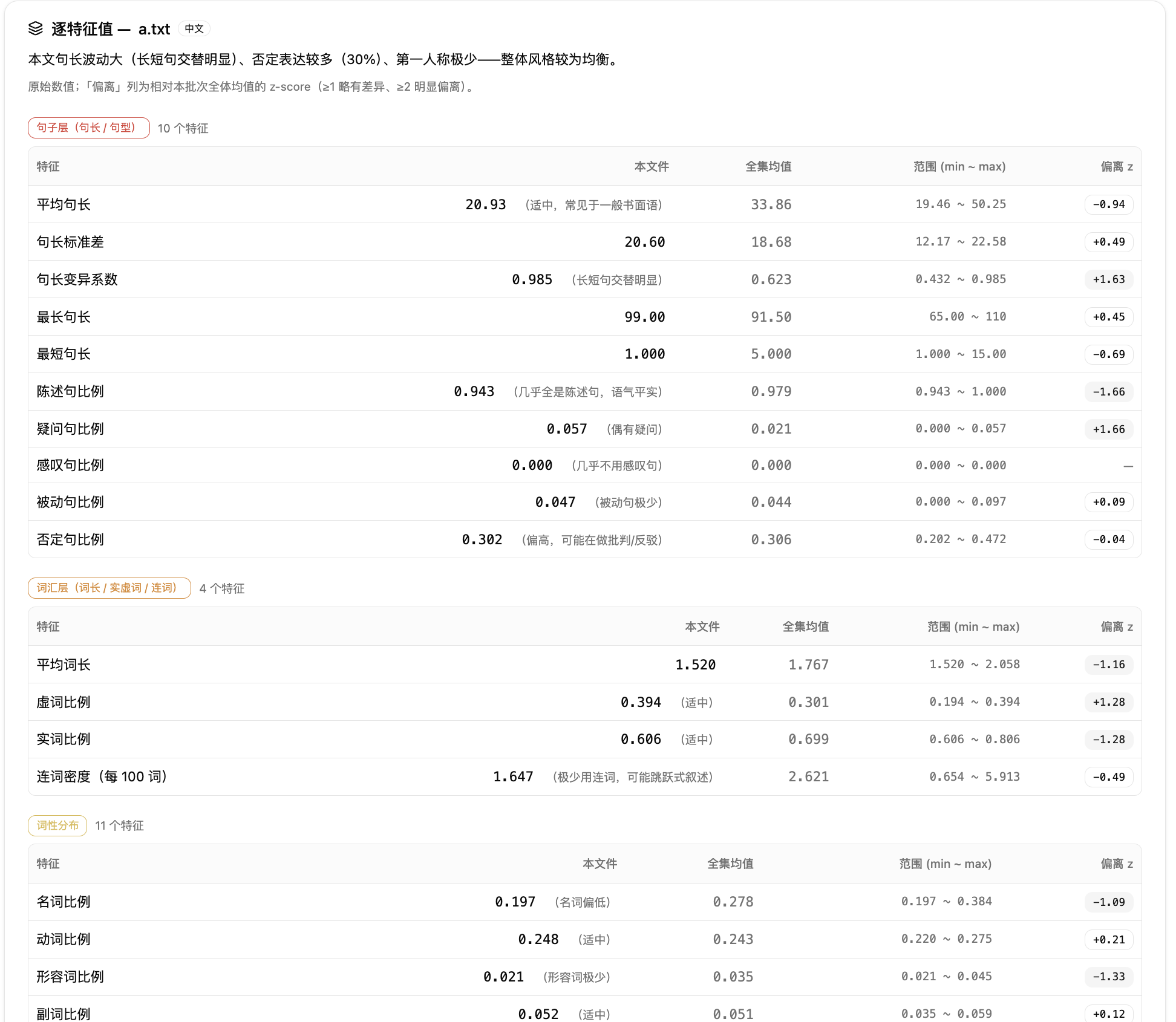
第七步:回到逐特征表。逐特征表会列出本篇原始值、参照均值、范围和偏离 z 值。z 值 ≥1 表示略有差异,≥2 表示明显偏离。多篇文本对比时,以这里为依据更稳。
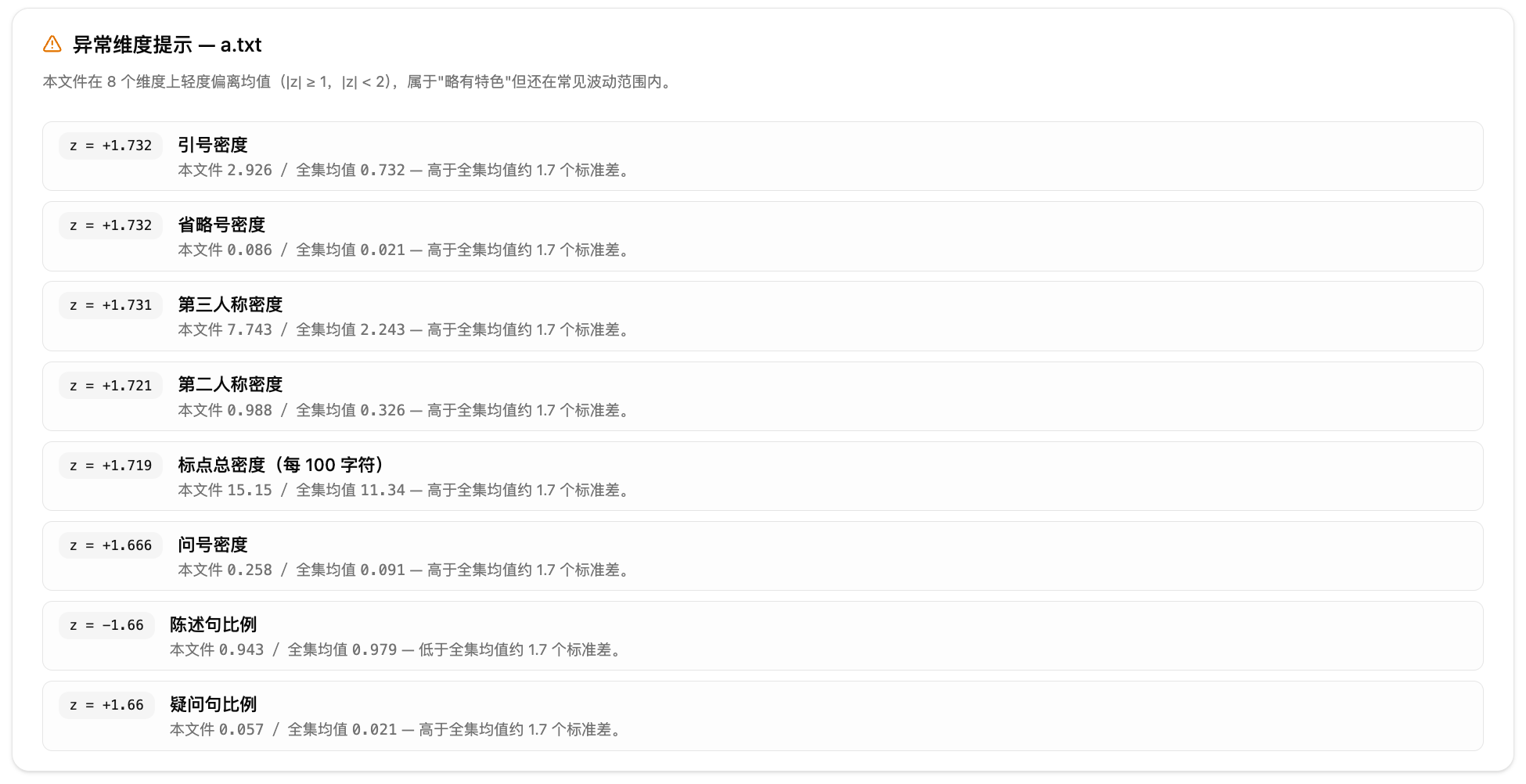
第八步:查看异常维度提示。异常维度不是错误,而是提醒你某篇文本在哪些写作习惯上和参照对象差得比较远。每个异常项会标注 z 值和严重程度。结合原文看,才能判断它是特色还是问题。
参数解析与对比示例
可配置参数如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 文本语言 | 自动检测、中文、英文;中英混排明显时更适合手动指定 | 自动检测 |
| 启用的特征组 | 可选句子层、词汇层、词性分布、标点风格、人称代词;至少保留 1 组 | 全部启用 |
| 0-1 标准化 | 将不同量纲的特征压到统一范围,便于雷达图和相似度比较 | 开启 |
| 智能分段 | 用于观察长文内部的风格波动 | 开启 |
| 每段目标字数 | 控制段落级波动曲线的窗口大小,范围 100 到 1000 | 200 |
| 基准风格 | 选择一篇作为参照,查看其他文本相对它的偏差 | 无,使用批次均值 |
五组特征含义如下。
| 特征组 | 主要指标 | 适合观察什么 |
|---|---|---|
| 句子层 | 平均句长、句长波动、最长句、最短句、陈述/疑问/感叹比例、被动和否定线索 | 句子节奏、正式程度、设问或情绪表达 |
| 词汇层 | 平均词长、虚词比例、实词比例、连词密度 | 信息密度、逻辑连接、书面语程度 |
| 词性分布 | 名词、动词、形容词、副词、介词、连词、助词、代词、数词、量词等比例 | 叙事感、描述感、名词化程度 |
| 标点风格 | 逗号、句号、问号、感叹号、分号、引号、括号、破折号、省略号密度 | 句内停顿、情绪强度、说明结构 |
| 人称代词 | 第一、第二、第三人称使用率 | 主观口吻、教程口吻、客观叙述程度 |
四组典型配置供参考。
- 改稿前后对照。把原稿作为基准,保持标准化开启。重点看终稿相对原稿在哪些维度下降或收敛,判断修改是否真的改善了句子节奏。
- 稿件统一。保持句子层、词汇层、标点风格和人称代词。先看顶部阈值判定,再看异常维度提示,定位哪几篇语气偏教程、偏营销或偏口语。
- 作者风格研究。保留全部特征组,重点看风格雷达和逐特征表中哪些维度差异最大。单看相似度读数不够,要结合具体指标判断写作习惯是否真的接近。
- 写作诊断。保留全部特征组,重点看句子层、标点风格和人称代词。把异常维度翻译成具体修改方向。
相似度阈值需要特别注意。报告中 ≥85% 才视为风格相似,<55% 才视为风格不相似,55% 到 85% 之间属于中间地带,不下结论。不要把「本批最高的一对」直接理解成相似,也不要把「本批最低的一对」直接理解成不相似,除非它们越过对应阈值。
案例分析
案例一:改稿前后风格对照。
背景:编辑有同一篇稿子的原稿、二改稿和终稿,想知道修改到底改变了什么。读起来终稿更顺,但不清楚是词汇变化、句长变化,还是标点变化。
配置:保留全部特征组,选择原稿作为基准。
结果:风格雷达显示终稿在句长和标点相关维度上更收敛。逐特征表显示终稿句长波动下降,标点密度也下降;基准对比进一步显示这些变化相对原稿更明显。
结论:这次改稿的核心是压缩拖沓句式、减少过密停顿,让表达节奏更稳定。编辑可以把这一结论写入改稿说明,也可以继续检查是否保留了必要细节。
案例二:多来源通稿风格统一。
背景:内容团队整理同一活动的多篇通稿,主题相近,但读起来有的像公告、有的像教程、有的像营销话术。
配置:保留句子层、词汇层、标点风格和人称代词,不设置基准。
结果:顶部解读按 ≥85% 和 <55% 两条阈值说明哪些文本对达到标准,哪些只是中间地带。异常维度提示显示两篇稿件第二人称密度偏高,疑问句比例也偏高,读起来更像教程或营销话术,不像客观通稿。
结论:团队不需要全面重写,只需要优先调整那两篇的称呼方式和句型。
案例三:审稿人定位论证跳跃。
背景:审稿人觉得一篇论文某些段落跳跃感强,逻辑不够连贯,但很难在审稿意见里具体展开。
配置:保留全部特征组,重点看句子层和词汇层。
结果:异常维度提示显示连词密度偏低、长短句交替明显。回到原文发现省略过渡句的段落确实更散。
结论:审稿意见可以从「逻辑不够连贯」细化到「补充过渡句」和「减少超长句」。审稿人能给出更具体、更可操作的修改建议。
案例四:学生作文写作诊断。
背景:老师觉得一篇作文「有点散」,学生问到底怎么改。
配置:保留全部特征组,重点看句子层、标点风格和人称代词。
结果:逐特征表显示句长波动偏大、标点密度偏高、第一人称使用较多。
结论:修改方向从「再紧凑一点」变成三个具体动作:拆掉超长句、减少连续逗号、收束主观表达。学生知道改哪里了。
类似功能对比
文体风格指纹、写作风格判定、文本可读性分析都和写作质量或风格有关,但关注点不同。
| 对比维度 | 文体风格指纹 | 写作风格判定 | 文本可读性分析 |
|---|---|---|---|
| 做什么 | 统计句长、词性、标点、代词等风格特征,并比较差异 | 判断文本更接近哪类写作风格 | 评估文本是否容易阅读 |
| 关注点 | 写作习惯的量化侧写 | 风格类型归纳 | 阅读难度、句词复杂度 |
| 典型问题 | 差异在哪里、改稿改了什么 | 这篇更像哪种风格 | 这篇难不难读 |
| 是否做作者鉴定 | 否,只给统计线索 | 否,侧重风格描述 | 否,侧重难度评估 |
| 典型场景 | 改稿对照、稿件统一、作者风格研究、写作诊断 | 风格分类、文本调性判断 | 面向读者的易读性检查 |
如果你想知道「差异在哪里、改稿改了什么」,用文体风格指纹。如果你想知道「这篇更像哪种风格」,再看写作风格判定。如果你想知道「这篇难不难读」,用文本可读性分析。三者可以连续使用,但不要把风格相似度当成作者身份结论。