规范化做的事情可以拆成四块。
- 繁简转换。基于专业词典做上下文判断,不是简单的一对一替换。比如"乾燥"会正确转成"干燥",不会变成"干躁"。支持 9 种模式,包括繁转简、简转繁、台湾繁体、港澳繁体等,也有自动检测模式——系统判断文本主体是繁是简,然后统一为目标体。碰到繁简混排的情况会给出警告,方便你抽查。
- 标点规范化。7 项独立规则,每项可以单独开关。包括全角数字和字母转半角、直引号转弯引号并校验配对、折叠多余空白、省略号和破折号统一写法。
- 数字转正文。把"3号线""2024年"这类数字+中文组合转成"三号线""二〇二四年"。系统会用大模型判断哪些组合是词、哪些该转,不是一刀切全转。
- 拼音转写。给中文字符标注拼音,支持声调符号、声调数字、无声调三种形式。开启按词切分后,基于分词结果标注,多音字的准确率会高不少。处理完会生成一份拼音 CSV,可以直接拿去排版或做语音合成。
报告页从上到下展示:规范化总览(整体统计加各模块说明)、标点子项修改分布条形图、每份文件的修改统计表、数字转正文记录表、原文和改后的并排对照。
适用文档
支持 TXT 和 CSV 两种格式。
- TXT 文件。按全文处理。编码建议用 UTF-8,乱码文件需要先转码。
- CSV 文件。自动识别文本列进行规范化,非文本列原样保留。
繁简转换对纯中文文本效果最好。中英文混排的文本,中文部分正常转换,英文不受影响。拼音转写也只覆盖中文字符,英文、数字和标点不参与标注。
适用情景
- 港台稿件出海。内容团队收到台湾或香港繁体稿件,需要统一成简体发布。用自动检测模式,系统判断主体为繁体后自动转简,两岸三地的用语差异基本能正确处理。
- 政策文件数字规范化。政策文件里"3号线""12号楼"这些数字+中文组合,如果直接做文本清洗,数字可能被当噪声删掉。先开数字转正文把它们变成中文写法,后续清洗就不会误删了。
- 教材拼音标注。出版社需要给语文教材整篇标拼音。选声调符号模式,开按词切分,系统自动处理大部分多音字,处理不了的会标复核警告供人工抽查。拼音 CSV 可以直接交付排版。
- 繁简混排语料预处理。从不同来源收集的文本繁简混用,直接做分词或词频统计,同一个概念会被拆成两个词条。先统一文字形态再分析,统计结果会准确很多。
使用步骤
第一步:上传文件。上传一个或多个 TXT 或 CSV 文件,系统逐文件独立处理。

第二步:查看报告。提交后系统自动处理,完成后跳转到报告页。从上到下:规范化总览、标点子项分布条形图、文件修改统计表、数字转正文记录表、原文和改后的并排对照。
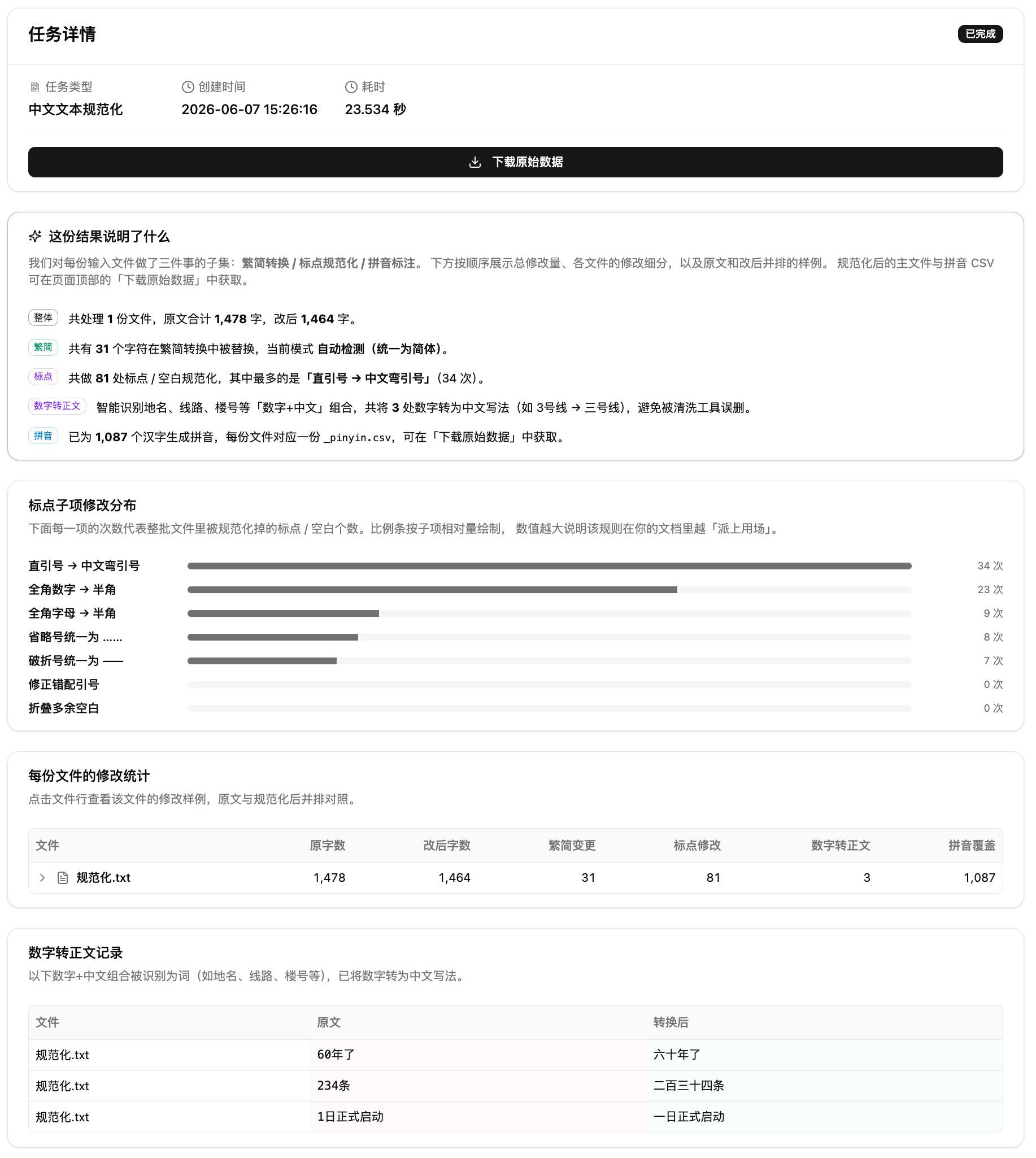
第三步:下载结果。点击下载拿到规范化后的主文件和拼音 CSV。建议先抽查对照预览,确认没误改再用于后续发布或分析。
参数解析与对比示例
繁简转换有 2 个参数。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 启用繁简转换 | 开启或关闭 | 开启 |
| 转换模式 | auto(自动检测)、t2s(繁→简)、s2t(简→繁)、s2tw/tw2s(台湾)、s2hk/hk2s(港澳)、s2twp/tw2sp(混合) | auto |
标点规范化有 7 项,每项独立开关。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 全角数字→半角 | 全角123转为半角123 | 开启 |
| 全角字母→半角 | 全角ABC转为半角ABC | 开启 |
| 直引号→弯引号 | ASCII 直引号按栈匹配转为中文弯引号 | 开启 |
| 修正错配引号 | 对已是中文引号的文本做栈式校验 | 开启 |
| 折叠多余空白 | 连续空格、全角空格、多余空行折叠 | 开启 |
| 省略号统一 | ...、⋯⋯等统一为 …… | 开启 |
| 破折号统一 | --、——等统一为 —— | 开启 |
其他参数有 4 个。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 数字转正文 | 大模型判断数字+中文组合是否为词,转为中文写法 | 关闭 |
| 拼音转写 | 开启或关闭拼音标注 | 开启 |
| 声调形式 | 声调符号(mā)、声调数字(ma1)、无声调(ma) | 声调符号 |
| 按词切分 | 基于分词结果标注拼音,多音字准确率更高 | 开启 |
三组典型配置供参考。
- 繁简统一。繁简转换设自动检测 + 全部标点规范化 + 拼音关闭。适合港台稿件出海,处理速度快。
- 拼音标注。繁简转换关闭 + 标点规范化 + 拼音转写(声调符号 + 按词切分)。适合教材拼音标注,输出规范化文本加拼音 CSV。
- 完整规范化。繁简转换设繁转简 + 全部标点规范化 + 数字转正文 + 拼音转写。适合政策文件或需要全面规范化的场景,处理时间会长一些。
案例分析
案例一:港台稿件出海统一。
背景:某内容团队收到 30 篇台湾繁体公众号稿件。
配置:繁简转换(自动检测)+ 全部标点规范化。
结果:系统识别主体为繁体并统一为简体。"軟體→软件""光碟→光盘""滑鼠→鼠标"等台湾用语正确转换,"乾燥→干燥"等多义字也处理对了。标点方面直引号转弯引号并校验配对,省略号和破折号统一。报告里繁简变更 1,247 处、标点修改 856 处、复核警告 23 处(都是繁简混排提示),编辑抽查警告项后即可发布。
案例二:政策文件数字规范化。
背景:某研究机构处理 50 份政策文件。
配置:数字转正文开启。
结果:系统提取所有"数字+中文"组合,用大模型判断哪些是词。"3号线→三号线""12号楼→十二号楼""2024年→二〇二四年"等共转换 342 处。报告展示数字转正文记录表,每处显示原文和转换后结果。这些文件后续做文本清洗时,已转为中文的数字不会被误删。
类似功能对比
中文文本规范化和文本清洗容易搞混,其实做的事情不一样。
| 对比维度 | 中文文本规范化 | 文本清洗 |
|---|---|---|
| 做什么 | 统一文字形态,修正不规范写法 | 删掉噪声,减少无关字符 |
| 怎么做 | 繁简转换、标点规范化、数字转正文、拼音转写 | 删除标点、停用词、HTML、emoji |
| 对原文影响 | 无损替换,一字不丢 | 删除字符,原文缩减 |
| 典型场景 | 繁体资料整理、拼音标注、发布前格式统一 | 爬虫去噪、建模前预处理 |
| 输出 | 规范文本 + 替换明细 + 拼音 CSV | 干净文本 + 删除统计 |
两者可以串联:先规范化统一文字形态,再清洗去噪声。繁简混排语料走这个流程比较合适。