文本矩阵分析做的事情可以概括成三步:定词表、看结构、回原文。
第一步是切段与分词。系统先把材料切成「文档段」,纯文本按词数窗口切段,CSV 则把每一行聚合成一个文档段,再分词、去停用词。切段的目的是给后面的统计一个「文档」单位,TF-IDF 和共现都依赖这个单位来计算。
第二步是挑出重要词。系统在文档—词条频数矩阵上做 TF-IDF(词频—逆文档频率)加权,挑出在本批材料里区分度最高的词,而不是单纯最频繁的词。常见的「的、了、我们」这类词在每段都出现,区分度低,会被压下去;只在部分文档里集中出现的词,往往更能代表材料的差异。你可以指定重点关注词,这些词即使词频不高,也会被优先保留进重要词表。
第三步是看结构、回原文。两个词在同一文档段里同时出现,就记为一次共现。系统把高共现的词对连成邻接强度矩阵和关系网络,再按「重要词之间是否存在共现边」做简易连通分组,方便你快速浏览话题块。每个重点词和高共现词对都配有原文证据,标注命中段落位置和代表片段,方便你回原文核对关联是否真的成立。报告会按你选择的使用场景(通用材料梳理、论文综述、问卷开放题、用户反馈、政策通知、访谈初筛、作文作业)组织阅读顺序和核对问题。
适用文档
这个功能更适合「多份、成批」的材料,而不是单篇长文。一批问卷开放题答案、几十场访谈转录、几十篇论文摘要、十几份政策文件,都是典型的输入。原因在于 TF-IDF 和共现都需要足够多的文档段做对比,材料越成批,区分度和共现强度越稳。单篇很短的文本切不出足够文档段,重要词和共现都容易失真,这时结果只能当作粗略参考。
文本质量会直接影响结果。网页导航、表头、页脚、重复模板和乱码会制造虚假的高频词和虚假共现,让一些格式词混进重要词表。一般来说,先把正文清理干净再分析,词表会更干净。如果你发现重要词里出现了大量符号或重复短语,通常是原文没清干净,建议回头检查。
语言和分词也要留意。中文需要先分词,专有名词如果被切开,会产生不存在的词对,比如把一个机构名拆成两个普通词后,它们的共现就失去了意义。遇到这种情况,可以用自定义词典把专名固定下来。英文材料同样可以处理。
预处理方面有两点值得检查。一是停用词,如果停用词表过窄,「的、了、和」这类词可能挤进词表,挤掉真正有信息量的词,可以补充停用词。二是词性过滤,如果你只想看名词和动词这类实词,可以在分词阶段过滤掉副词、连词、介词等虚词,让词表更聚焦。
使用步骤
第一步:先想清楚你要回答的问题。问卷开放题通常问「用户最集中提的是什么」;文献综述通常问「该用哪些词作为分类起点」;政策材料通常问「哪些概念是稳定表述、哪些只是套话」;访谈初筛通常问「该从哪些概念开始编码」。问题不同,选的场景和看的指标也不同。
第二步:选择使用场景。在「你准备用它做什么」里选一个最接近的场景。这个选择只影响报告的阅读顺序、核对问题和下一步建议,不改变分词、矩阵和共现的计算结果,所以可以放心按用途选。
第三步:设定展示的重要词数量和重点关注词。重要词数量可在 10~50 之间调,材料杂、想多看一些就调大,想聚焦头部就调小。如果你心里已经有几个必须盯住的词,填进重点关注词,它们即使词频不高也不会被筛掉。
第四步:读顶部的「先看这三件事」。这块按你选的场景给出三个落点:哪些词适合写进标题或摘要、哪些词经常一起出现、先回原文核对哪里。它是整份报告的导航,先看它能少走弯路。

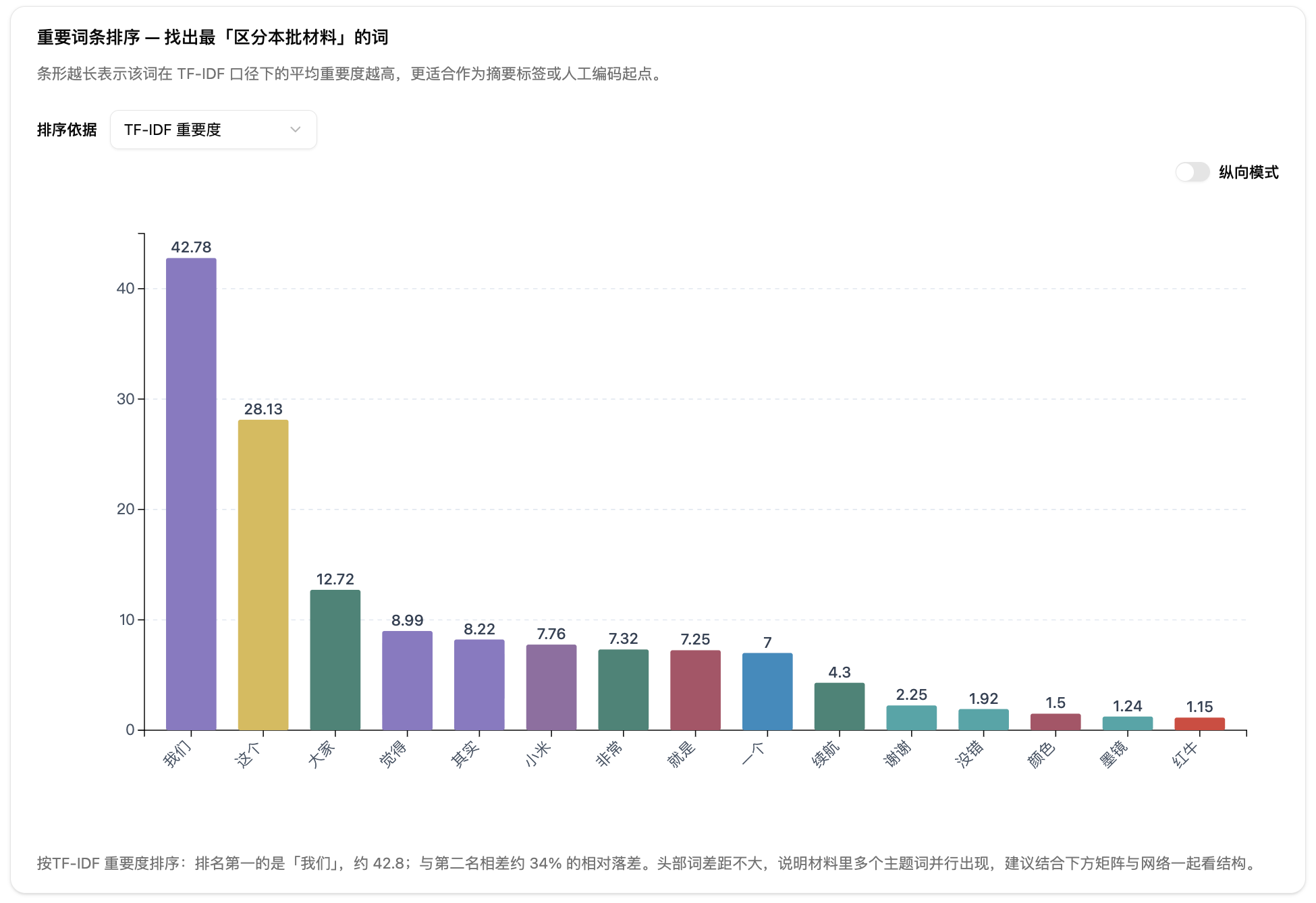
第五步:看重要词条排序条形图。条形越长,说明该词在 TF-IDF 口径下的平均重要度越高。你可以把排序依据在 TF-IDF 重要度、词频、文档覆盖率之间切换,交叉验证一个词到底是真重要,还是只是某一篇里特别多。
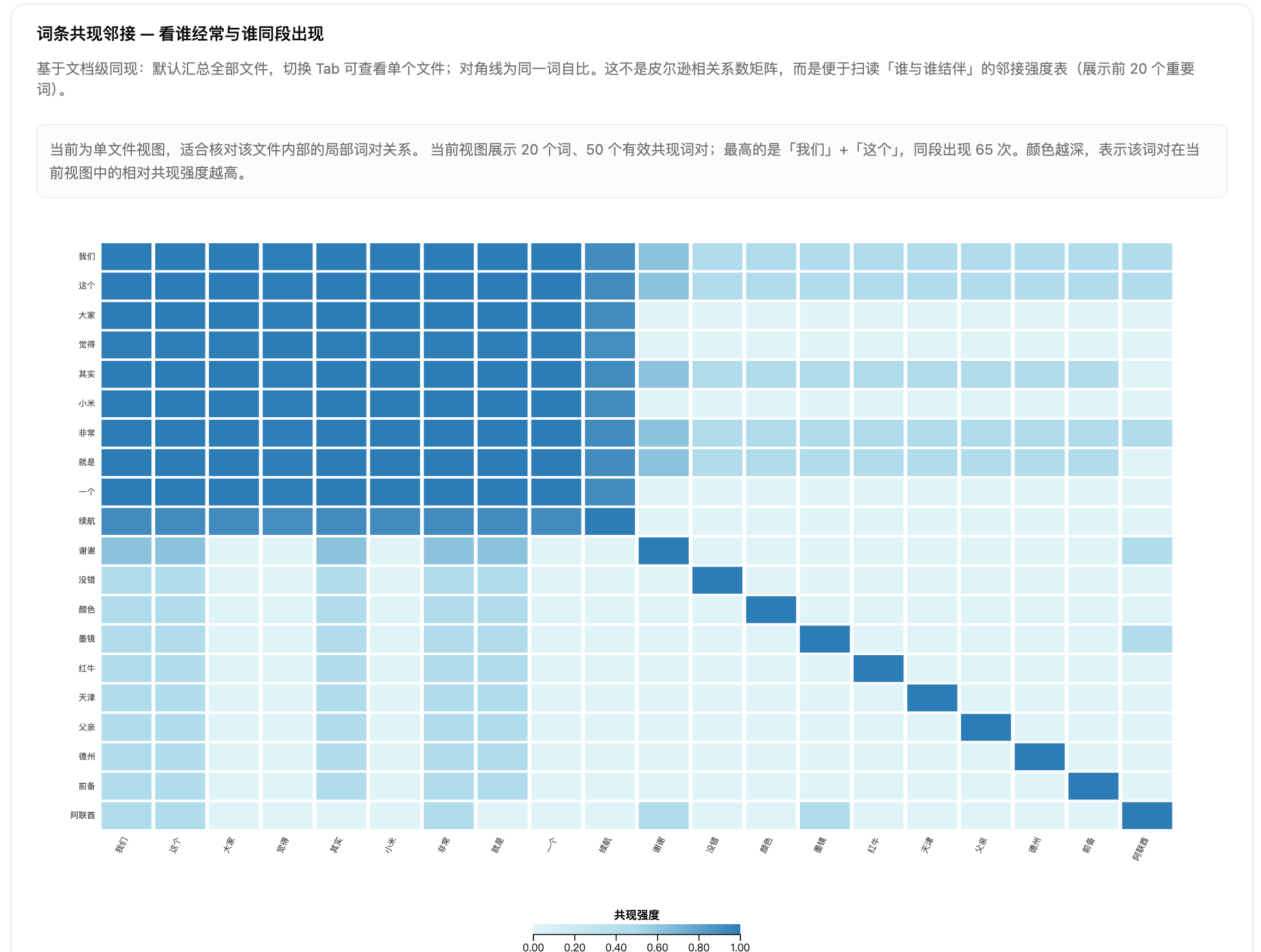
第六步:看词条共现邻接热力图。颜色越深表示两个词同段出现得越多,对角线是词和自己比。这里要注意,它不是皮尔逊相关系数矩阵,而是便于扫读「谁与谁结伴」的邻接强度表。上传多份文件时,可以切换 Tab 看单个文件或全部文件汇总。
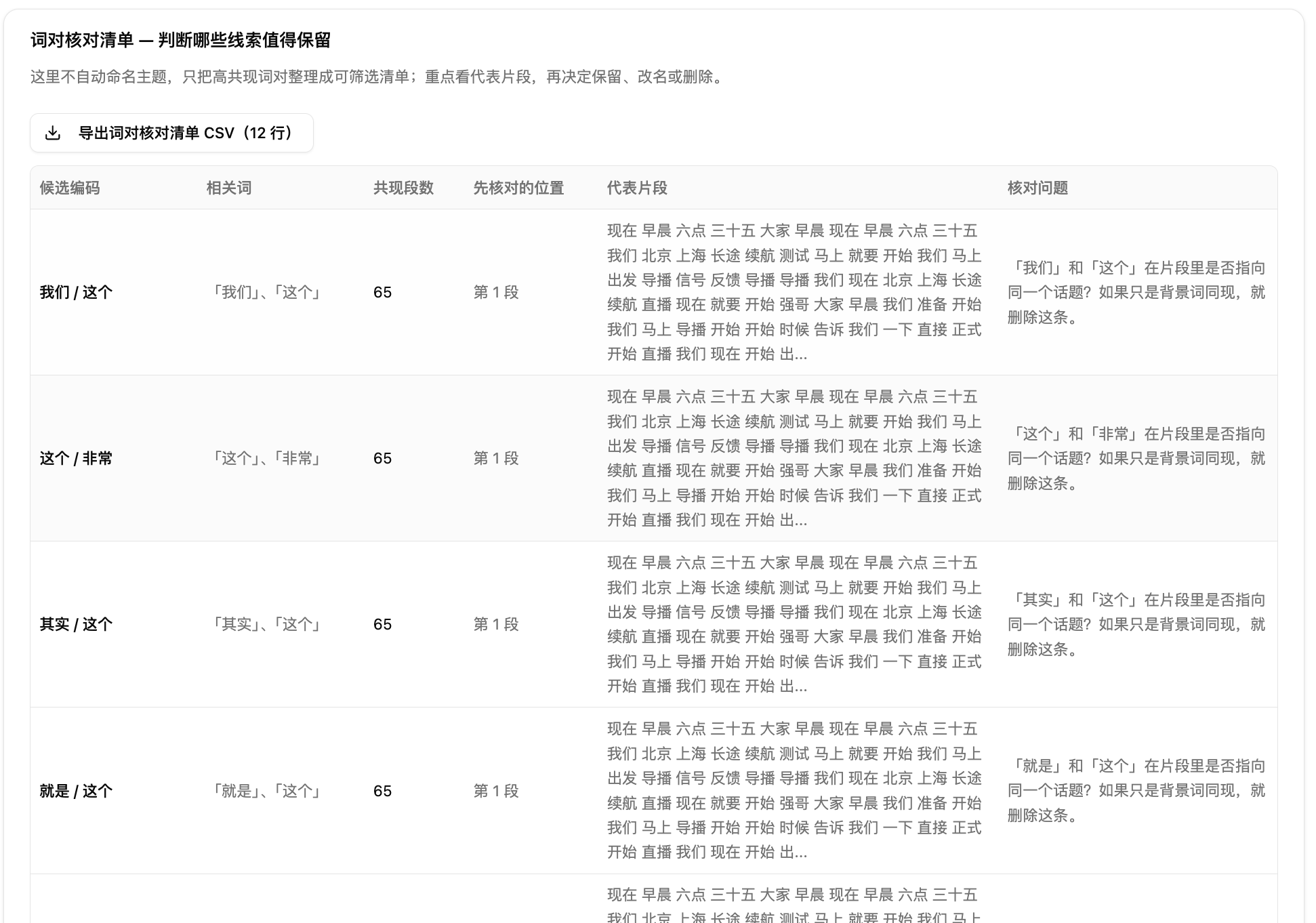
第七步:用词对核对清单和原文证据定位回原文。词对核对清单把高共现词对整理成可筛选清单,列出候选编码、相关词、共现段数、代表片段和核对问题,但不自动命名主题。你顺着代表片段回原文,结合核对问题判断这条线索是保留、改名还是删除。原文证据定位则可以单独选一个重点词或词对,查看它命中的位置和片段。确认无误后,可以导出强共现编码手册或词对核对清单的 CSV,带进后续编码工作。
第八步:看词汇关系网络。节点是重要词,连线表示经常同现,节点越大重要度越高。你可以把网络节点数在 10~30 之间调,节点少看主干,节点多看细节,拖动节点能展开局部结构,从图上判断材料里有哪些议题簇。
第九步:看详细统计。这里分三个标签页。文档信息给出文档段数、平均段内词数和矩阵稀疏度;词汇统计给出不同词语总数、入选重要词列数和文档间的余弦相似度;共现分组按连通分量把重要词分块。平均相似度高,说明材料写得像同一类;偏低,说明内容比较散,可能要分组解读。

第十步:参考下一步建议。报告底部会推荐能接着用的工具,帮你把词表变成统计结论或主题结构。
参数解析与对比示例
可配置参数如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 使用场景 | 决定报告的阅读顺序、核对问题和下一步建议,不改变分词、矩阵和共现计算 | 通用材料梳理 |
| 展示的重要词数量 | 保留并展示的重要词条数,可在 10~50 之间调 | 20 |
| 重点关注词 | 指定后即使词频不高也优先保留进重要词表,最多 20 个 | 空 |
| 分词模式 | 精确模式 / 全模式 / 搜索引擎,影响切词粒度 | 精确模式 |
| 词性过滤 | 选中的词性在分词阶段被过滤掉,仅支持中文 | 不过滤 |
| 自定义词典 | 让专有名词不被切开,固定为一个词 | 不启用 |
| 自定义停用词 | 过滤掉不想统计的词 | 不启用 |
三组典型配置供参考。
- 问卷开放题快速编码。场景选「问卷开放题 / 课堂反馈」,重要词数量调到 25 左右,开启词性过滤、只留名词和动词。这样词表更贴近用户真正提到的对象和动作,配合词对核对清单可以快速搭出编码类别。
- 文献综述定主题词。场景选「论文综述 / 文献摘要」,重要词数量调到 10~15,先看头部词作为综述小节候选。如果你已经锁定几个研究方向的关键词,填进重点关注词,确保它们留在表里。
- 政策概念结构梳理。场景选「政策 / 通知材料」,重要词数量调到 30 左右,把机构名、专有术语加进自定义词典避免被切开。重点看共现分组,判断哪些概念抱成一团、是否构成稳定表述。
案例分析
案例一:访谈初筛,快速建立编码候选。
背景:一位社会学研究者做了 30 场半结构化访谈,转录近 10 万字,不知道该从哪些概念开始编码。
配置:场景选「访谈初筛 / 编码准备」,重要词数量设 30,把几个理论上关心的概念填进重点关注词。
结果:系统挑出 30 个重要词条,并生成词对核对清单,每一对都标注了命中段落位置和原文片段。研究者顺着核对清单逐条回原文确认关联是否成立,把不成立的词对删掉。
结论:核对清单把「从哪开始编码」这件事变成了可逐条判断的任务,原本预计三周的初筛编码,压缩到一周左右完成。
案例二:问卷开放题,快速提取高频需求。
背景:一个产品团队分析 200 条问卷开放题答案,想知道用户最集中的诉求,但不知道从哪开始归类。
配置:场景选「问卷开放题 / 课堂反馈」,重要词数量设 25,开启词性过滤只留实词。
结果:重要词条排序里「退换货」「物流」「客服」排在前列;共现热力图显示「退换货」和「尺码」同段出现得很密。团队回原文核对后,确认这批反馈里尺码相关的退换占了不小比例。
结论:团队据此把「尺码相关退换」单独立为一个编码类别,归类的工作量明显减少。
案例三:政策文件,发现核心概念结构。
背景:一个研究团队分析 15 份行业政策文件,想分清哪些是稳定表述、哪些只是套话。
配置:场景选「政策 / 通知材料」,重要词数量设 30,把行业专名加进自定义词典。
结果:共现分组显示「监管—合规—风险」和「创新—发展—平台」分属两个连通分量,详细统计里的平均文档相似度约 0.18,说明两类政策话语确实存在差异。
结论:团队据此把材料分成两组分别解读,并在报告里补充了两套话语结构的对比。
类似功能对比
文本矩阵分析、高频词提取、词语共现分析都和「词」有关,但落点不同。
| 对比维度 | 文本矩阵分析 | 高频词提取 | 词语共现分析 |
|---|---|---|---|
| 做什么 | 定区分度高的核心词,再看词与词的共现结构 | 按频次和占比统计最常出现的词 | 在窗口内扫描词对,用统计指标判断搭配是否可靠 |
| 关注点 | 重要词 + 共现结构 + 文档相似度 | 单个词的出现频率 | 词对搭配的统计显著性 |
| 典型问题 | 这批材料从哪开始读、从哪开始编码 | 这批材料里什么词最常出现 | 这两个词的搭配稳不稳 |
| 输出 | 重要词条排序、共现热力图、关系网络、核对清单 | 高频词表和占比 | 词对搭配表、分组聚类、搭配网络 |
| 典型场景 | 编码候选准备、主题词筛选、概念结构梳理 | 高频词表、简单对比 | 话语口径对比、概念关联验证 |
如果你想要的是「先定一份重要词表,再看它们怎么抱团」,用文本矩阵分析。如果只想看「什么词最常出现」,用高频词提取更直接。如果你已经有词、想确认「这两个词搭不搭」,用词语共现分析做更精细的统计判断。三者可以接力:先用文本矩阵分析定词表、看结构,再用高频词提取或词语共现分析在重点词上深入。