文本清洗做的事情,用一句话概括就是:把原始文本里不该有的东西删掉。
具体来说,处理过程分三步走。
1. 先做字符级清理。移除 emoji、零宽字符、控制字符,全半角标点统一,连续标点合并。
2. 再做内容级过滤。按你勾选的选项删除标点、停用词、数字或换行符。停用词就是"的""了""是"这类对分析没什么用的常见词。
3. 最后做结构化处理。强力清理会剥离 HTML 标签只保留中文;文本分段会按字数窗口切分长文本。
处理完你会看到一份报告:处理了多少文件和行数、删了多少字符、原文和清洗后的对照预览。被删掉的内容用红色高亮标出来,方便你快速判断。
适用文档
目前支持两种输入格式。
1. TXT 文件。按行处理,每行一条记录。编码建议用 UTF-8,其他编码出现乱码可以先转一下。
2. CSV 文件。自动识别文本列清洗,非文本列原样保留。需要带表头。
PDF、Word、Excel 暂时不直接支持,可以先使用辅助工具中的转换工具转成 TXT 或 CSV 再用。
强力清理会把非中文内容全部删掉,包括英文、数字和空格。文本里有英文术语或金额编号的话,就别开这个。
适用情景
1. 爬虫文章。HTML 标签、导航链接、广告代码,用强力清理加过短行过滤和停用词,噪声会少很多。
2. 访谈转录稿。"嗯""然后""就是说"不少,自定义停用词表加上这些词,配合文本分段,文本会规整不少。
3. 主题建模准备。LDA 通常需要先去标点和停用词;BERTopic 取决于模型,可以都试试。
4. 中英文混排文档。标点统一后后续分词更准确。
使用步骤
第一步:上传文件。上传一个或多个 TXT 或 CSV 文件,系统逐文件独立处理。
第二步:查看报告。报告展示处理概览、字符统计、数据解读三个卡片,以及文件详情表和清洗对照预览。
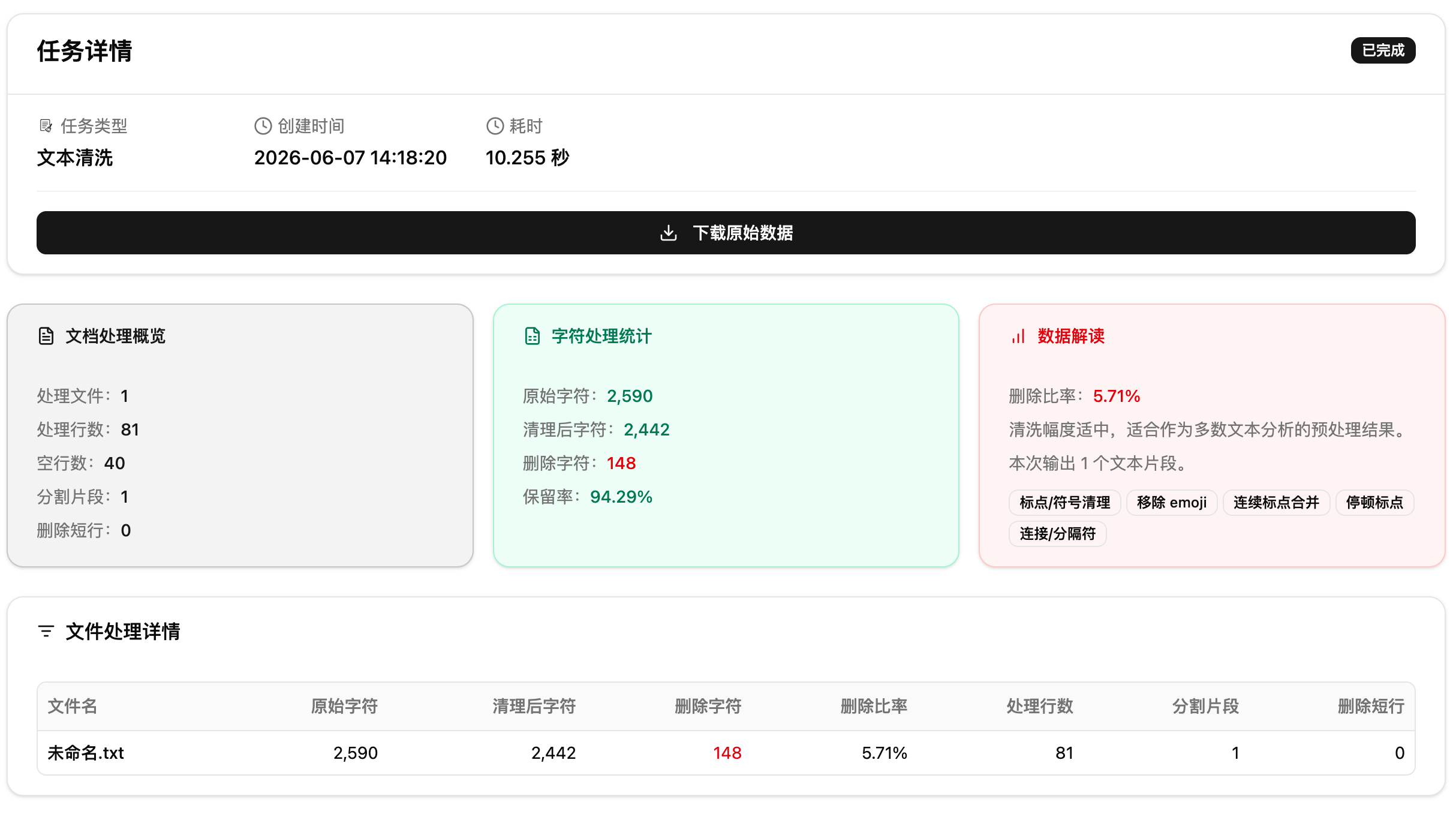

第五步:下载结果。在报告页点击下载获取清洗后的文件,建议抽查对照预览确认无误后再用于后续分析
参数解析与对比示例
标点清理参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| 移除 emoji | 删除所有 emoji 表情符号 | 开启 |
| 全半角标点统一 | 将英文标点统一为中文全角标点 | 关闭 |
| 连续标点合并 | 将重复的标点合并为一个 | 开启 |
| 句末标点 | 删除 。!?.!? | 关闭 |
| 停顿标点 | 删除 ,、;:,;: | 开启 |
| 括号引号 | 删除 ()()【】[]{}《》<>""''等 | 关闭 |
| 连接/分隔符 | 删除 —、–、_、/、\、|、·、…、~、~ 等 | 开启 |
| 其他符号 | 删除 Unicode 分类为标点或符号的其他字符 | 关闭 |
其他清洗参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| 清除换行 | 将记录内部换行符替换为空格,TXT 不同行仍独立处理 | 关闭 |
| 清除数字 | 删除所有数字字符 | 关闭 |
| 删除过短行 | 删除字数低于指定阈值的行 | 关闭 |
| 过短行阈值 | 低于该字数的行会被删除 | 5 字 |
| 文本分段 | 按字数窗口切分长文本 | 关闭 |
| 分段窗口大小 | 切分片段的字数 | 200 字 |
| 强力清理 | 剥离 HTML 标签并仅保留中文 | 关闭 |
| 停用词过滤 | 删除内置或自定义停用词表中的词语 | 关闭 |
| 使用内置停用词表 | 使用系统预置中文常用停用词表 | 需先启用停用词过滤 |
| 自定义停用词表 | 上传自定义停用词文件,每行一个词,与内置词表合并使用 | 未上传 |
典型配置对比:
1. 轻度清洗。移除 emoji + 停顿标点 + 连接符 + 连续标点合并。适合文本较干净、只去多余标点。删除比率一般 5%-10%。
2. 标准清洗。加停用词过滤 + 删除过短行(阈值 8 字)+ 文本分段(200 字)。适合 LDA / BERTopic 输入准备。删除比率一般 15%-25%。
3. 深度清洗。加强力清理 + 句末标点 + 括号引号。适合纯中文爬虫或 OCR 文本,有英文术语或金额就别开强力清理。删除比率一般 30%-50%,建议看对照预览。
比率是经验参考,实际效果受文本类型影响。
案例分析
案例一:爬虫数据去噪。
背景:某研究团队从新闻网站抓取 200 篇财经报道,文本混杂 HTML 标签和导航链接。
配置:强力清理 + 删除过短行(阈值 10 字)+ 移除停用词。
结果:保留率约 65%。HTML 标签基本清除,中文正文保留较完整。导航文字等中文噪声还需要结合过短行和停用词处理,建议抽查。
结论:清洗后跑 LDA 主题建模,主题词更集中,无关词少了很多。
案例二:访谈转录稿预处理。
背景:某社科研究者有 15 份访谈转录稿,口语化填充词不少。
配置:自定义停用词表 + 停顿标点删除 + 文本分段(250 字)。
结果:保留率约 78%,每份切为 12-20 个片段。
结论:清洗后用于 BERTopic 主题聚类,可结合主题词评估口语噪声干扰。
类似功能对比
文本清洗与中文文本规范化容易混淆,区别如下:
| 对比维度 | 文本清洗 | 中文文本规范化 |
|---|---|---|
| 处理目标 | 去除噪声,减少无关字符 | 统一文字形态,修正不规范用法 |
| 核心操作 | 删除标点、停用词、HTML、emoji | 繁简转换、异体字统一、格式归一 |
| 典型场景 | 爬虫去噪、建模前预处理 | 繁体资料整理、历史文献数字化 |
| 输出结果 | 删除后的干净文本 + 删除统计 | 替换后的规范文本 + 替换明细 |
两者可串联:先规范化统一文字形态,再清洗去除噪声,适用于繁简混排语料。文本清洗不等同于分词或去重,主要负责去除噪声,为后续分析准备输入。