依存句法分析做的事情是:把每句话拆成词语,标出词语之间的支配和被支配关系,用弧线连接并标注关系类型。
处理过程可以理解成三步。
- 先分词和标注。系统把句子切成词语,对每个词语标注它在句子里扮演的句法角色:是主语、谓语、宾语,还是定语、状语、补语等修饰成分。
- 再建立依存关系。每个词语都有一个支配词(除了句子的核心谓语),支配词和被支配词之间的连线就是依存弧,弧上标注关系类型,比如主谓关系、动宾关系、定中关系、状中关系等。
- 最后计算复杂度。系统根据依存树的深度、依存弧的长度和关系类型的分布,给出句法复杂度评分(0-10 分,越高越复杂),并把句子分成简单句、中等复杂句和复杂句三档。
报告的核心是可视化依存关系图。每棵树用弧线连接词语,弧线方向从支配词指向被支配词。点击任意词语,可以高亮它的支配词和所有依存弧,快速定位这个词语在句子里的位置。关系类型包括主谓、动宾、定中、状中、动补、介宾、并列等,覆盖汉语常见的句法结构。
适用文档
政策文件和法律文本很适合用依存句法分析。这类文本的特点是句子长、修饰成分多、嵌套结构深。读者经常遇到「一句话读了三遍还是抓不住主干」的情况。依存关系图可以把长句的骨架可视化,拆句建议可以告诉你怎么把复杂句拆成简单句。
新闻报道适合。新闻导语通常信息密度高,一句话里塞了时间、地点、人物、事件多个成分。依存分析可以快速判断导语的主干是否清晰,修饰成分是否过多。
学术论文适合。学术写作中常见的问题是从句嵌套过深、定语过长导致主语和谓语隔得太远。依存分析可以定位这些结构问题,帮助作者简化表达。
语言教学适合。老师讲解「把」字句、「被」字句、连动句、兼语句等特殊句式时,依存树可以直观展示这些句式和一般主谓句的结构差异。学生看到弧线比听定义更容易理解。
文本质量方面,正文越完整、标点越准确,分析结果越稳定。没有标点的长段落会被当作一个句子处理,复杂度评分会偏高。乱码、表格符号和非文字内容会干扰分词和依存标注,通常先清理正文再分析更稳。
语言方面,目前支持中文。英文依存分析需要不同的模型和关系体系,暂不支持。中文分词质量直接影响依存结果,专有名词如果被拆开,会产生错误的依存弧。
使用步骤
第一步:先明确你要回答的问题。编辑通常问「这句话的主干在哪里、怎么简化」;老师通常问「这个句式的结构和一般主谓句有什么不同」;研究者通常问「这批文本的句式复杂度有多高、不同来源之间有没有差异」。
第二步:上传文本。文本需要含正确标点,系统按句号、问号、感叹号等标点自动分句。如果文本没有标点,分析结果会不准确。
第三步:阅读总览。总览区域显示总句数、平均句长和句法复杂度评分。评分范围 0-10,分数越高说明句子结构越复杂。一般来说,5 分以下属于简单到中等,5 到 7 属于中等偏复杂,7 以上属于复杂。

第四步:查看依存关系占比。报告会按比例展示各类依存关系的分布:主谓、动宾、定中、状中、动补等。如果定中和状中占比特别高,说明文本中修饰成分较多,句子可能偏长。
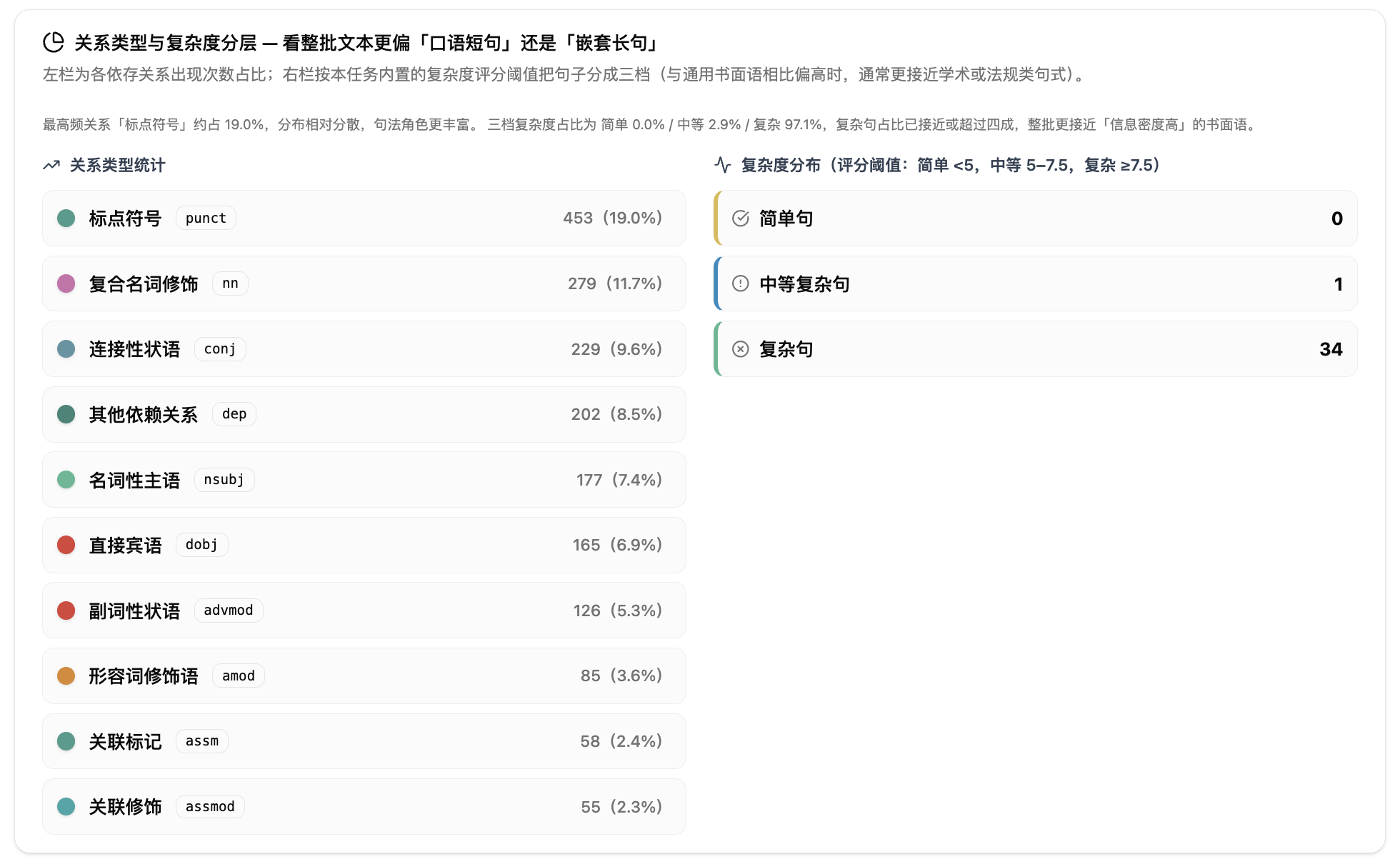
第五步:查看句子分档。系统把全文句子自动分成简单句、中等复杂句和复杂句三档。可以按复杂度或句长排序浏览,快速定位最复杂的句子。
第六步:逐句查看依存树。点击任意句子,可以展开它的依存关系图。弧线连接词语并标注关系类型,点击词语可高亮其支配词与依存弧。这一步适合精确定位句子的主干和修饰结构。
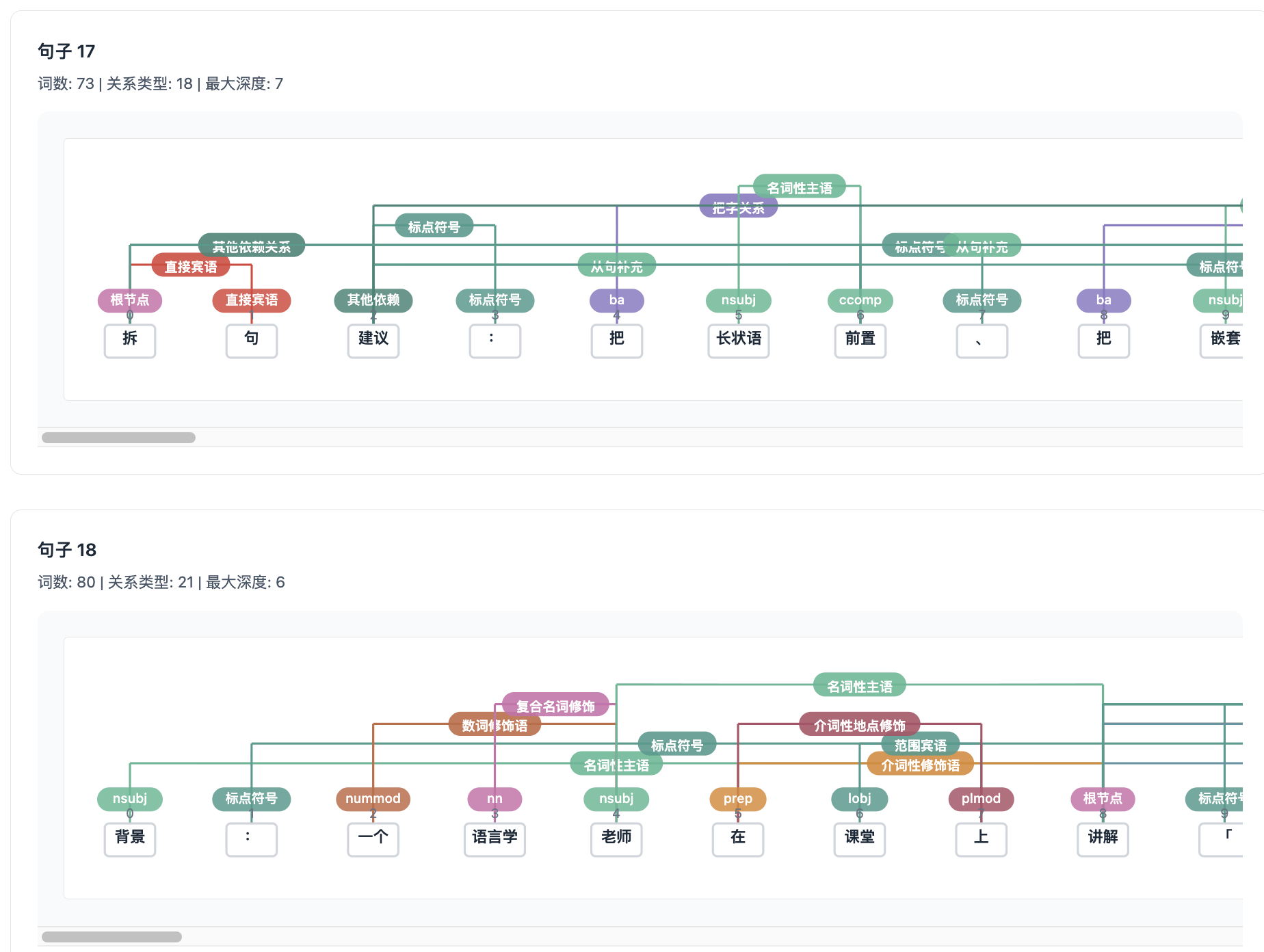
第七步:查看拆句建议。对复杂句开启拆句建议后,系统会分析哪些修饰成分可以前置、哪些嵌套结构可以拆开,给出具体的简化方向。建议是结构层面的,不替你改写具体措辞。

第八步:对比多篇文本。上传多个文件后,可以比较不同文本的句法复杂度评分、平均句长和依存关系分布。适合对比不同作者、不同时期或不同来源的句式差异。
第九步:参考下一步建议。报告底部会推荐文体风格指纹、文本可读性分析等后续工具,帮助你进一步分析写作风格或阅读难度。
参数解析与对比示例
可配置参数如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 分句标点 | 用于切分句子的标点符号,可选句号、问号、感叹号、分号 | 句号、问号、感叹号 |
| 复杂度阈值 | 简单句和复杂句的分界分数,低于此值为简单句,高于为复杂句 | 5 |
| 拆句建议 | 是否对复杂句自动生成简化建议 | 关闭 |
| 排序方式 | 按句长、复杂度或原文顺序浏览句子 | 原文顺序 |
四组典型配置供参考。
- 编辑改稿。开启拆句建议,复杂度阈值保持 5。重点看复杂句的拆句建议,把长状语前置、嵌套定中拆开,改写后重新分析确认复杂度下降。
- 语言教学。关闭拆句建议,按原文顺序浏览。重点看依存关系图,用不同句式的依存树对比讲解句法结构差异。
- 句式对比。上传多篇文本,按复杂度排序。重点看复杂度评分和依存关系分布,比较不同来源的句式差异。
- 长难句筛查。复杂度阈值设为 7,只看复杂句。快速定位文本中最难读的句子,逐个查看依存树和拆句建议。
复杂度评分的含义需要特别注意。评分基于依存树的深度、依存弧的长度和关系类型的分布综合计算。深度越深说明修饰嵌套越多,弧长越长说明词语之间的距离越远,这两者都会推高复杂度。但评分只是结构层面的指标,不等于「写得好不好」。简单句不一定写得好,复杂句不一定写得差——关键看表达目的是否需要那么复杂的结构。
案例分析
案例一:政策文件长难句改写。
背景:一个编辑在处理政策文件时,遇到一段 80 字的长句,读了三遍还是抓不住主干。想知道这句话到底在说什么、怎么改写更清晰。
配置:开启拆句建议,复杂度阈值保持 5。
结果:依存关系图显示这句话有两层嵌套的定中结构和一个长状语,谓语动词被埋在中间。句法复杂度评分为 8.2,被标记为复杂句。拆句建议:把长状语前置、把嵌套定中拆成两句。
结论:编辑按建议改写后,复杂度评分从 8.2 降到 5.1。句子骨架清楚了,读者不用反复读就能抓住主干。
案例二:语言学课堂句式对比。
背景:一个语言学老师在课堂上讲解「把」字句、「被」字句和一般主谓句的结构差异,纯讲定义学生听不懂。
配置:关闭拆句建议,按原文顺序浏览。
结果:三棵依存树清楚展示了「把」字句中宾语前置的依存弧、「被」字句中主语被动化的依存弧,以及一般主谓句的简单主干。学生第一次看到句子的骨架,比背定义有效多了。
结论:依存关系图可以作为语言教学的可视化工具,帮助学生理解抽象的句法概念。
案例三:新闻导语结构检查。
背景:一个编辑团队在审稿时发现部分新闻导语信息密度过高,一句话塞了时间、地点、人物、事件多个成分,读者需要反复阅读。
配置:复杂度阈值设为 6,开启拆句建议。
结果:50 篇导语中有 12 篇被标记为复杂句。依存关系图显示这些导语的共同特点是状语过长(时间状语和地点状语叠加)或主语前有多个定语。拆句建议集中在「把时间状语独立成句」和「减少主语前的定语层数」。
结论:编辑团队据此建立了导语写作规范:状语不超过两个、定语不超过一层。后续新稿件的平均复杂度评分下降了 1.8 分。
类似功能对比
依存句法分析、文体风格指纹、文本可读性分析都和文本结构或质量有关,但关注点不同。
| 对比维度 | 依存句法分析 | 文体风格指纹 | 文本可读性分析 |
|---|---|---|---|
| 做什么 | 逐句标出词语之间的支配和被支配关系 | 统计句长、词性、标点、代词等风格特征 | 评估文本是否容易阅读 |
| 关注点 | 句子内部的语法结构 | 写作习惯的量化侧写 | 阅读难度、句词复杂度 |
| 典型问题 | 这句话的主干在哪、怎么简化 | 差异在哪里、改稿改了什么 | 这篇难不难读 |
| 输出 | 依存关系图、复杂度评分、拆句建议 | 风格雷达、逐特征表、异常维度提示 | 可读性分数、难度等级 |
| 典型场景 | 长难句改写、句式教学、句式对比 | 改稿对照、稿件统一、作者风格研究 | 面向读者的易读性检查 |
如果你想知道「这句话的结构是什么样的」,用依存句法分析。如果你想知道「这篇的写作风格和另一篇差在哪里」,用文体风格指纹。如果你想知道「这篇难不难读」,用文本可读性分析。三者可以连续使用:先用可读性分析判断难度,再用依存分析定位结构问题,最后用风格指纹看整体写作习惯。