评估器做的事情分成两个层面,分别面向不同需求。
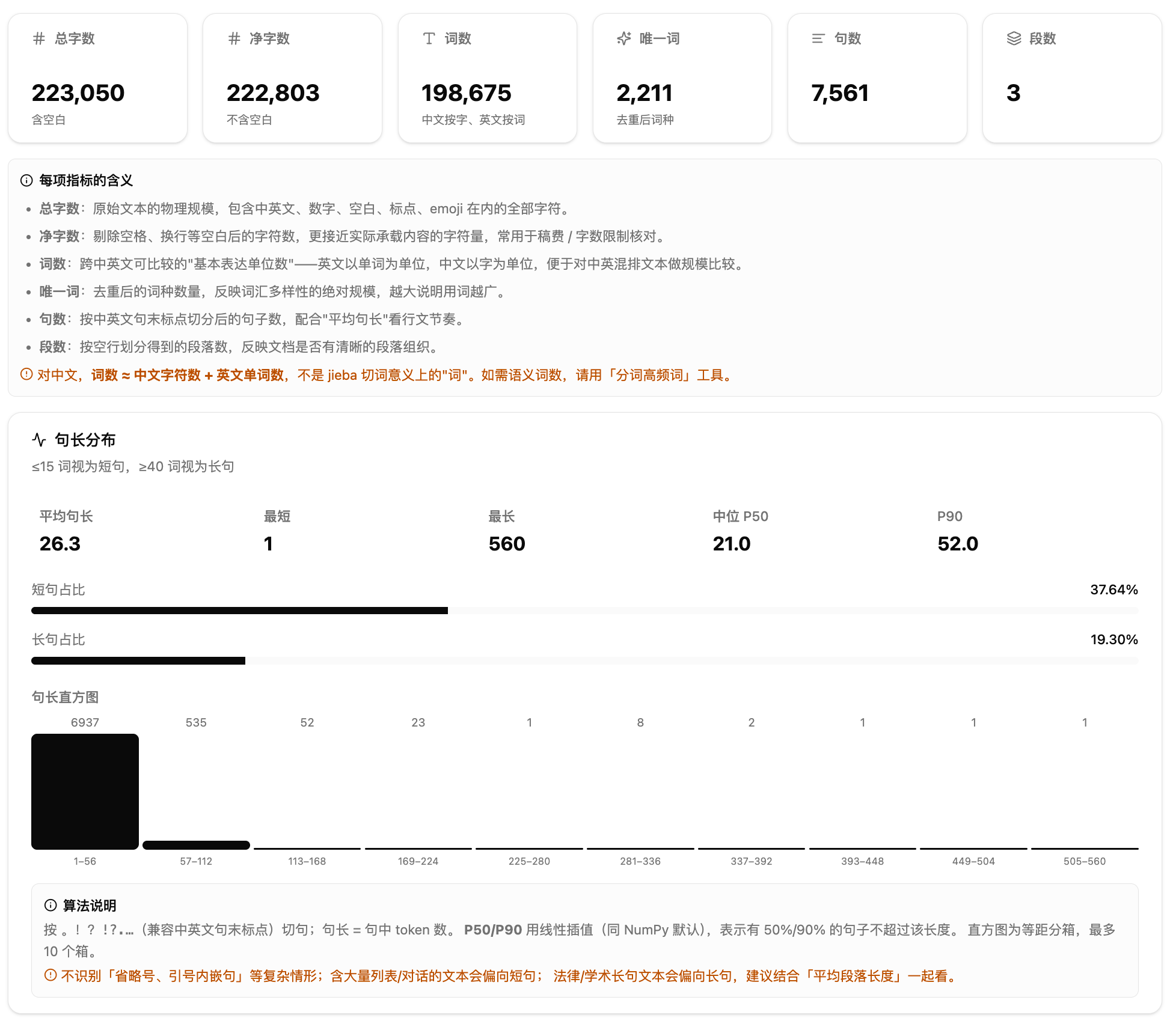
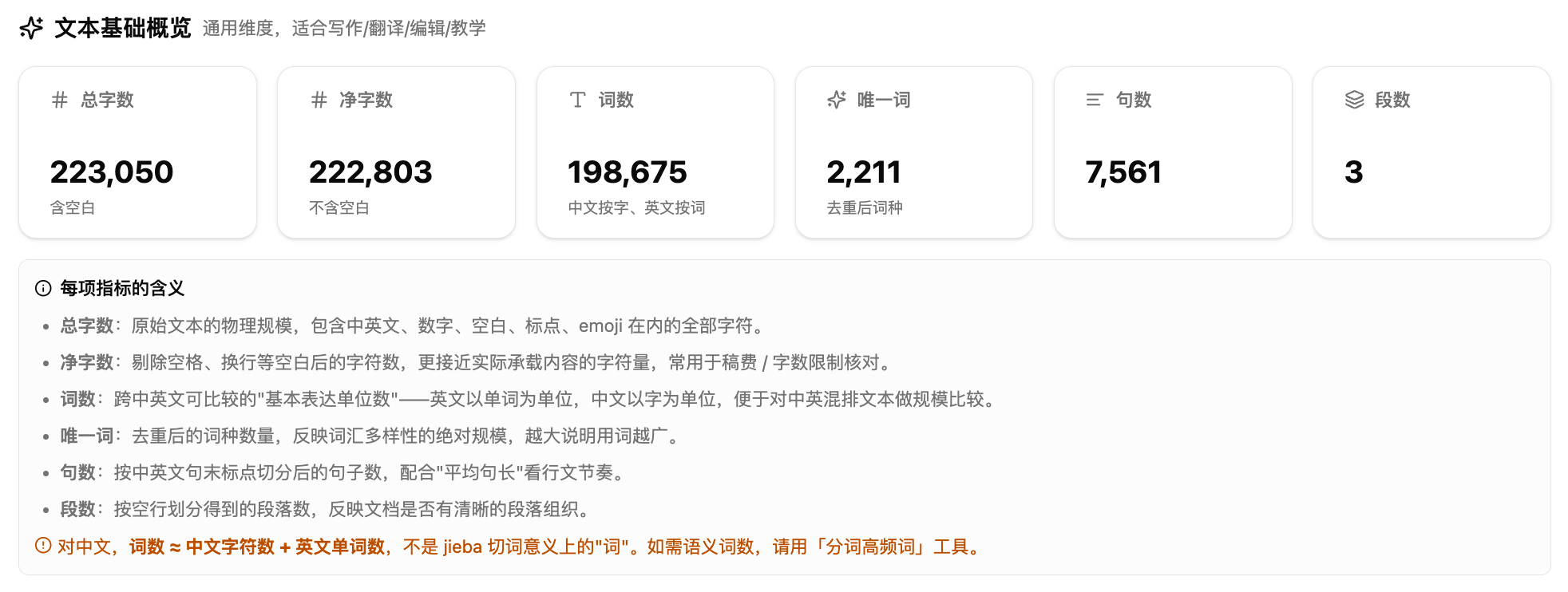
第一个层面是"文本基础概览",面向写作和编辑场景。它统计文本的基本规模——总字数、净字数、词数、唯一词、句数、段数——然后从三个角度展开分析。
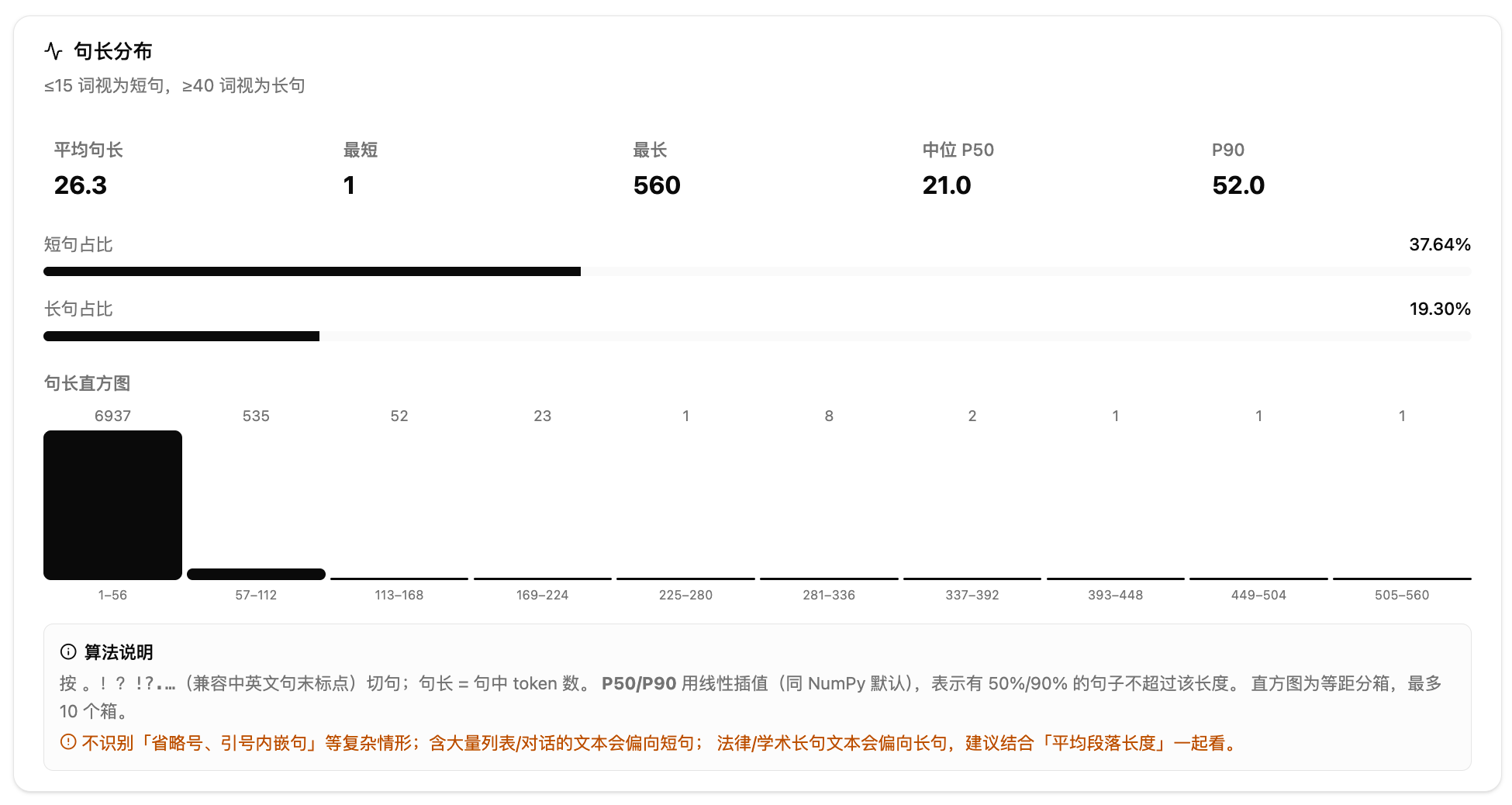
句长分布方面,按中英文句末标点切句,计算平均句长、P50 和 P90 句长,统计短句(15 词以内)和长句(40 词以上)各占多少比例,并画一张等距分箱直方图。
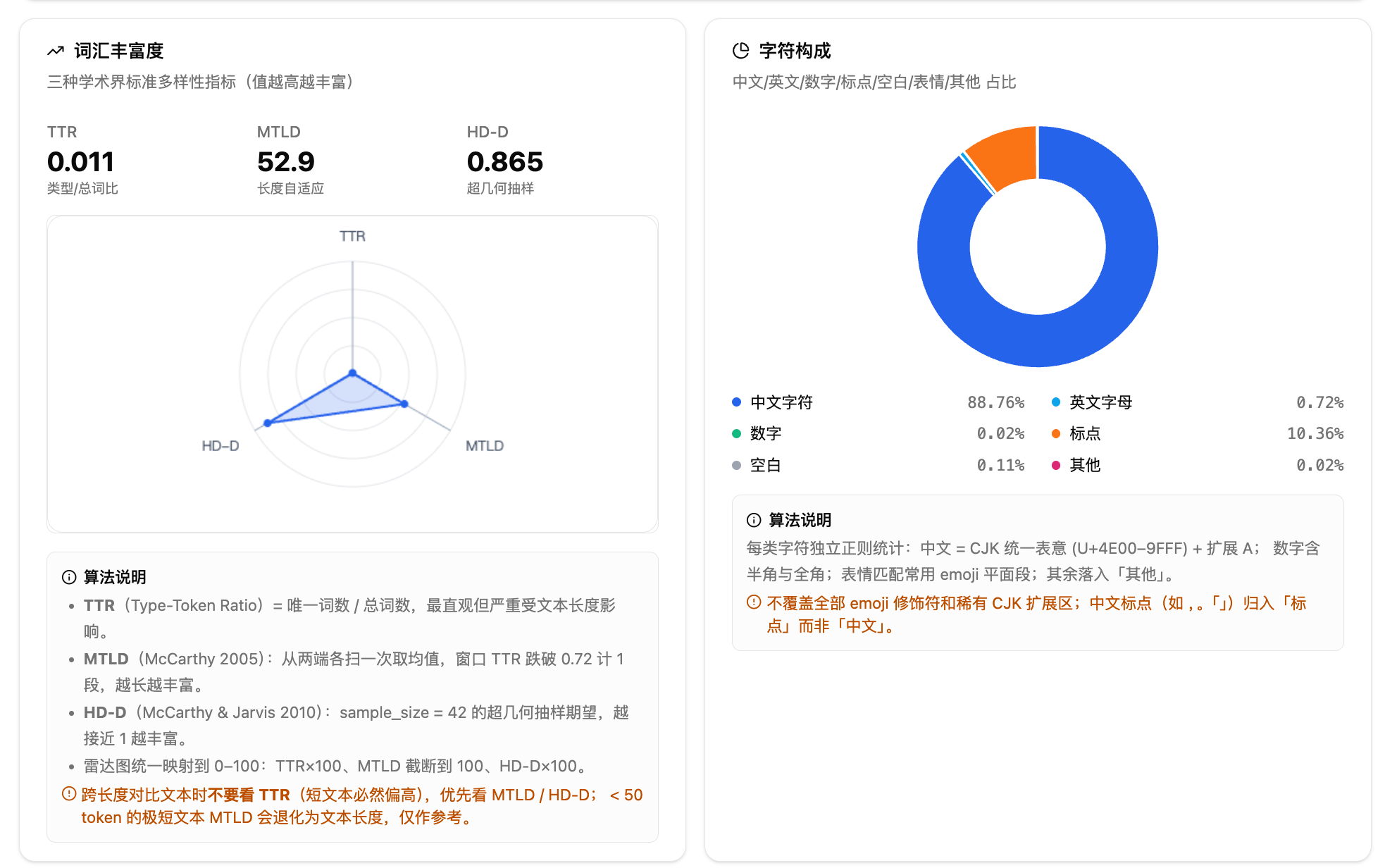
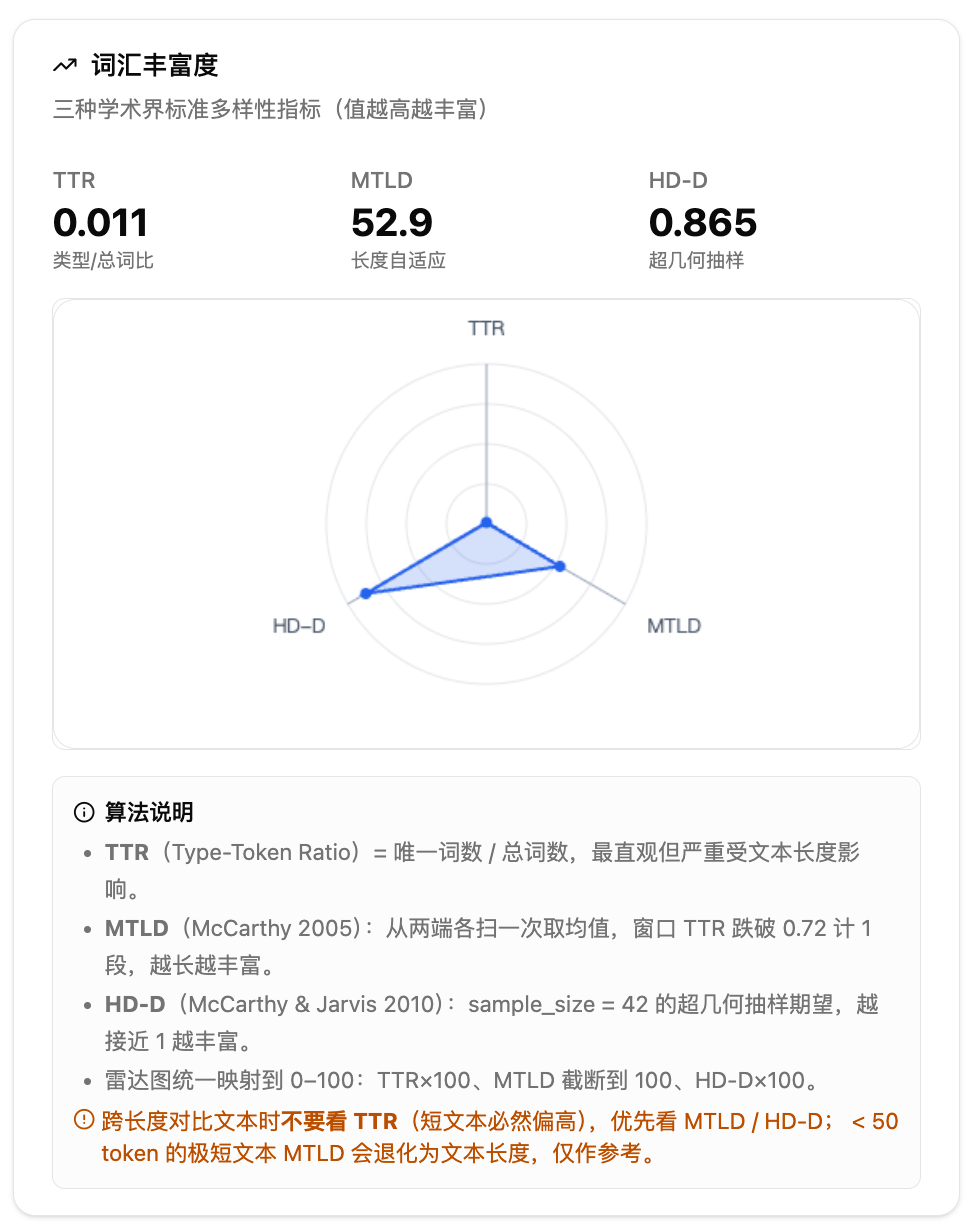
词汇丰富度用三个学术界标准指标衡量:TTR(类型-总词比,最直观但受长度影响大)、MTLD(长度自适应,跨文件可比性更强)、HD-D(超几何抽样,消除长度偏差),三个指标还会绘制成雷达图方便对比。
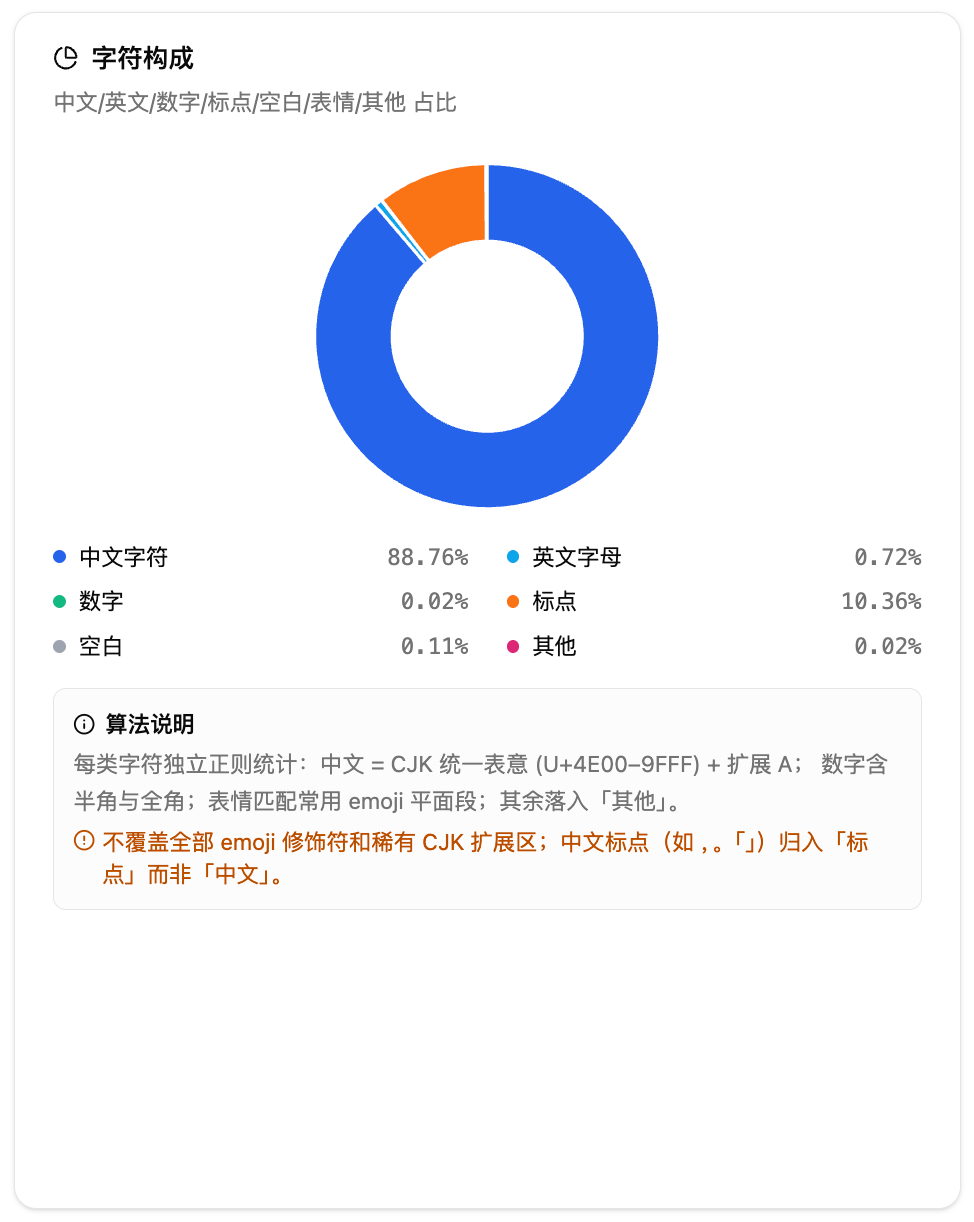
字符构成用环形图展示中文、英文、数字、标点、空白、表情、其他各自占比。另外还有全半角标点统计,方便判断排版规范度。
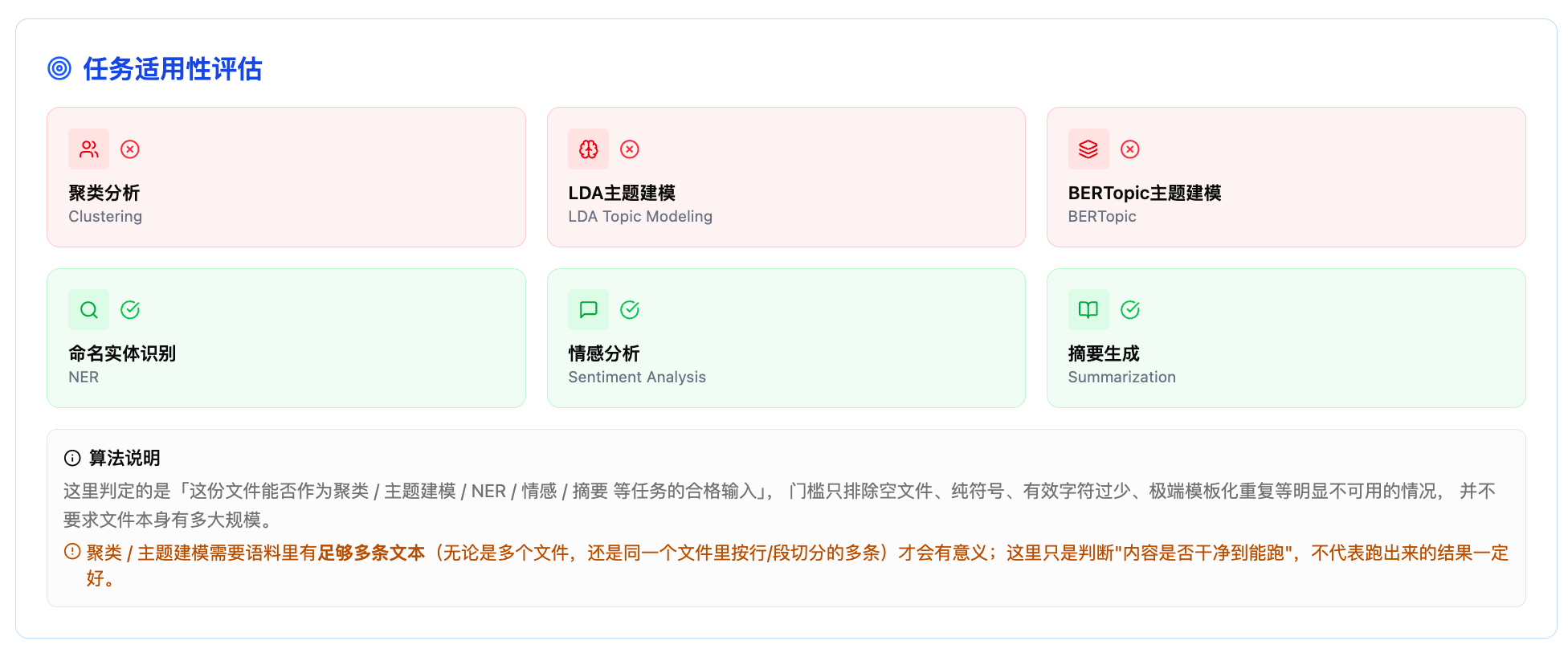
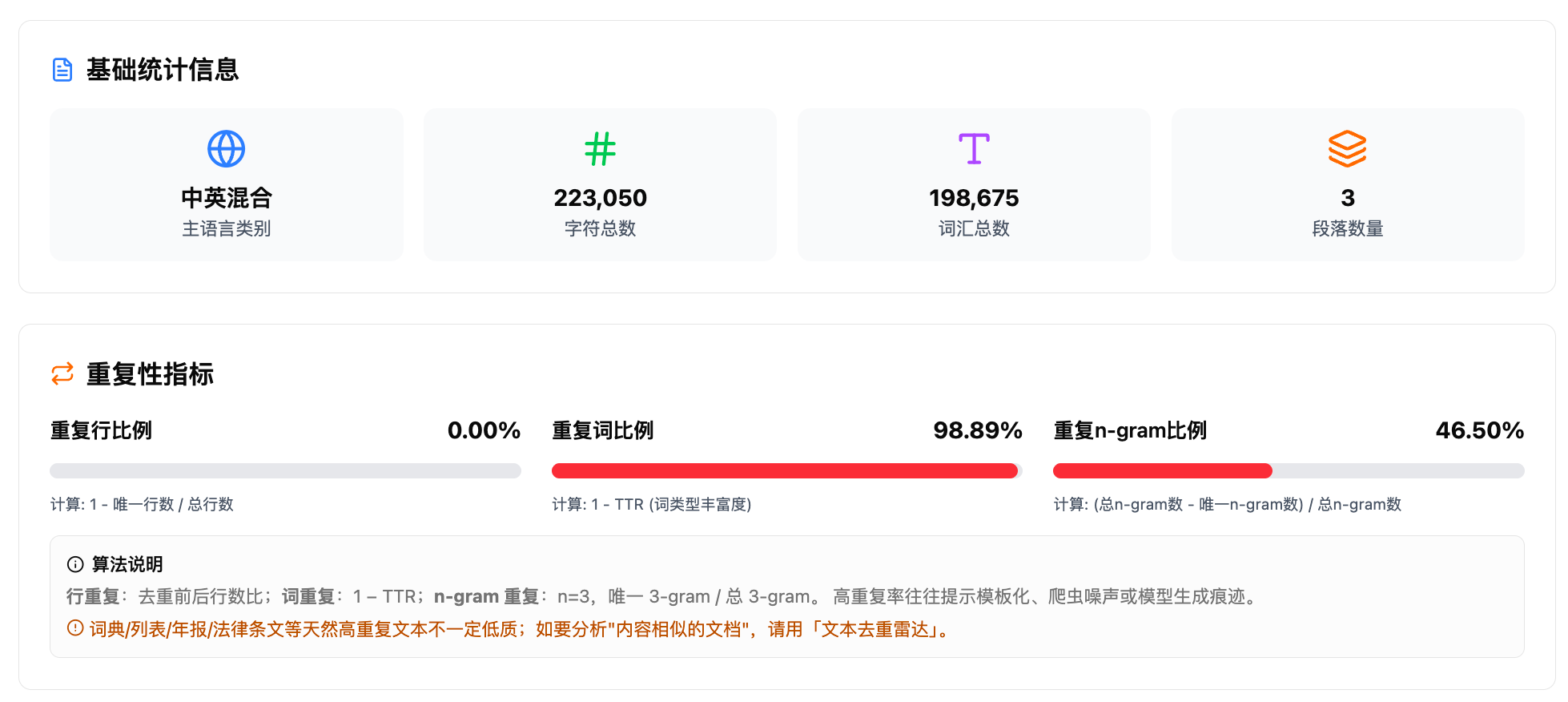
第二个层面是"NLP 任务适用性体检",面向技术场景。它从 100 分起步,按符号占比、有效字符、句长段长、词汇丰富度、重复率、信息熵等维度逐项扣分,给出综合得分和 good/fair/poor 三档评价。然后按"语料是否干净到能跑"的最低门槛,分别判定这份文本能否作为聚类、LDA、BERTopic、命名实体识别、情感分析、抽取式摘要六种任务的合格输入。
判定只排除空文件、纯符号、极重复模板这些明显不可用的情况,不要求文件有多大。NLP 体检部分还细分为六个指标分组:基础统计、重复性检测、文本组成分析、词汇质量评估、结构特征提取、信息密度计算,每个分组独立展示。
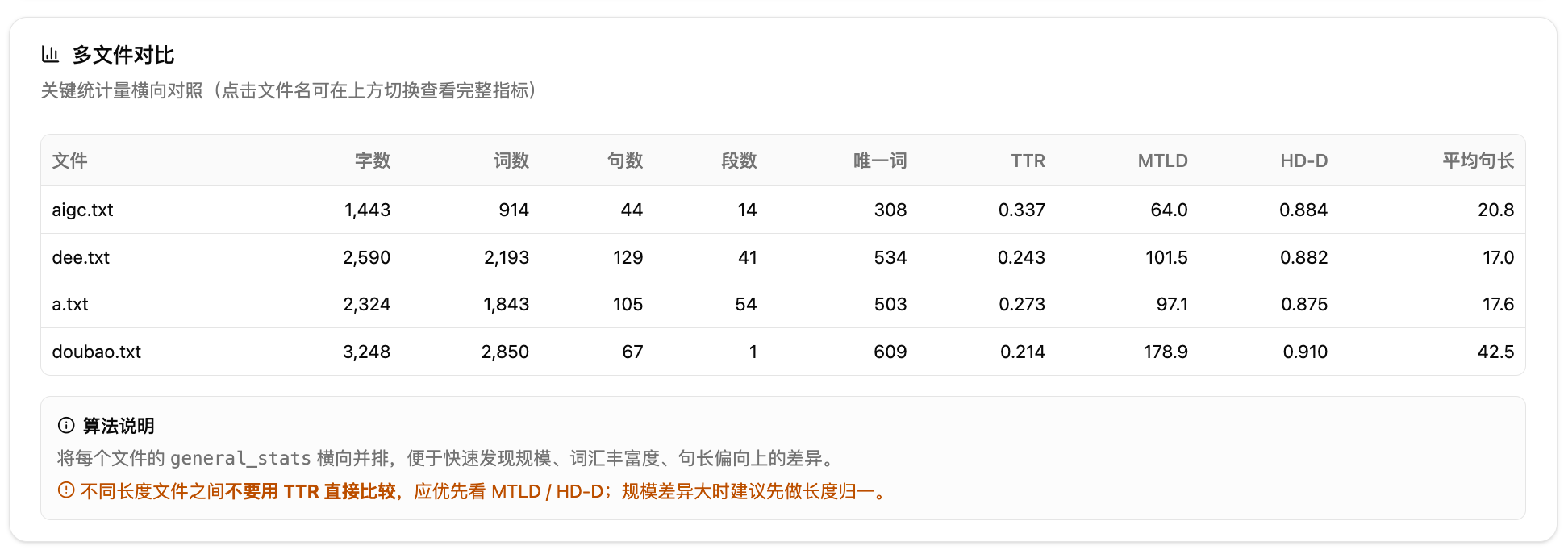
上传多个文件时,自动展示横向对比表,按字数、词数、句数、段数、唯一词、TTR、MTLD、HD-D、平均句长九个维度对照。每个指标区块都附带算法说明和注意事项,帮助你理解计算逻辑和适用边界。
适用文档
支持 TXT 和 CSV 两种格式。
- TXT 文件。按全文处理,编码建议用 UTF-8。其他编码出现乱码可以先转码再上传。
- CSV 文件。自动识别文本列进行评估,非文本列不影响结果。需要带表头。
适用情景
- 主题建模前摸底。你打算用 LDA 或 BERTopic 做主题分析,但不确定手头语料质量够不够。跑一次评估器,看看综合得分和任务适用性判定,心里有数再往下走,避免跑出一堆噪声主题。
- 多份语料横向对比。你从不同渠道收集了几份语料,想快速比较哪份质量更好。上传多个文件,看综合得分和词汇丰富度指标,就能分出高下,再决定用哪份或者怎么混合。
- 爬虫数据质量检查。爬回来的文本可能夹杂大量噪声、重复内容或模板化文本。评估器的重复性指标(重复行比例、重复词比例、重复 n-gram 比例)能帮你快速发现问题,知道哪些站点的数据需要先做清洗。
- 写作质量参考。翻译稿、学术论文、公众号文章等,可以用词汇丰富度(TTR、MTLD、HD-D)和句长分布来评估用词多样性和行文节奏,发现用词单一或句子过长的问题。
- 语料库批量审核。做学术研究时需要建一个规范的语料库,评估器可以批量扫描每份文本的质量,筛除不合格样本,统一标准后再进入分析流程。
使用步骤
第一步:上传文件。你可以上传一个或多个 TXT 或 CSV 文件,系统逐文件独立评估。

第二步:查看报告。提交后系统自动处理,完成后跳转到报告页。报告页从上到下依次展示:结果说明提示、文本基础概览(规模数字卡、句长分布直方图、词汇丰富度雷达图、字符构成环形图、标点全半角统计、多文件对比表),以及 NLP 体检(综合得分、任务适用性六项判定、基础统计、重复性指标、文本组成、词汇质量、结构特征、信息密度)。
第三步:下载结果。报告页提供 CSV 导出,包含所有指标的完整数据。建议先看综合得分和任务适用性,再根据需要深入查看各个指标分组。
报告解读
报告页信息量比较大,这里按区域逐一说明怎么看、看什么。
1.文本基础概览——规模数字卡。六个数字一排:总字数是原始文本的全部字符数(含空白标点),净字数剔除了空白,更接近实际承载内容的量。词数的口径是"中文字符数加英文单词数",不是语义分词意义上的"词",如果你需要语义词数,可以用分词高频词工具。唯一词反映词汇多样性的绝对规模,越大说明用词越广。句数和段数配合平均句长一起看,能判断行文节奏。
2.文本基础概览——句长分布。先看平均句长和 P50/P90 句长。P50 表示有一半句子不超过这个长度,P90 表示有九成句子不超过这个长度,两者差距大说明句长参差不齐。再看短句占比和长句占比:短句多可能是口语或对话类文本,长句多可能是学术或法律文本。直方图帮你快速看出句长集中在哪个区间。注意:按中英文句末标点切句,不识别省略号内嵌句等复杂情形,含大量列表的文本会偏向短句。
3.文本基础概览——词汇丰富度。TTR 最直观但受文本长度影响大,短文本天然偏高,跨文件比较时不要看 TTR。MTLD 和 HD-D 对不同长度的文本可比性更强,是跨文件比较的首选。雷达图把三个指标映射到 0-100 方便直观对比,多文件上传时可以叠加查看。不到 50 个词的极短文本,MTLD 会退化为文本长度本身,仅作参考。
4.文本基础概览——字符构成。环形图展示中文、英文、数字、标点、空白、表情、其他各自占比。中文占比高说明是中文为主的内容,英文占比高可能是中英混排或英文文档。标点占比异常高可能意味着格式问题。注意:这个统计的分类口径和 NLP 体检里的"文本组成分析"不完全一致,这里偏排版视角,那边偏 NLP 视角,差异属正常。
5.文本基础概览——标点全半角。全角标点多是中文排版规范的体现,半角标点多不一定有问题——如果文本含大量代码、URL 或英文术语,半角计数自然偏高。

6.文本基础概览——多文件对比表。多文件上传时自动出现,按字数、词数、句数、段数、唯一词、TTR、MTLD、HD-D、平均句长九个维度横向对照。快速发现哪份文件规模异常、哪份词汇丰富度偏低。不同长度文件之间不要用 TTR 直接比较,应优先看 MTLD 和 HD-D。
7.NLP 体检——综合得分。页面中间的大数字就是综合得分,75 分及以上是 good(绿底),60 到 74 是 fair(黄底),60 以下是 poor(红底)。得分是启发式累计扣分的结果,从 100 分起步逐项减分。古文、口语、对话、代码、表格类样本可能被误判为低质,需要结合文本基础概览综合判断。

8.NLP 体检——任务适用性。六张卡片分别对应聚类、LDA、BERTopic、命名实体识别、情感分析、抽取式摘要。绿色对勾表示通过(该文本可以作为这项任务的合格输入),红色叉号表示不通过。门槛只排除空文件、纯符号、有效字符过少、极端模板化重复等明显不可用的情况。聚类和主题建模还需要语料里有足够多条文本(多文件或同一文件内多行多段)才有意义,这里只是判断"内容是否干净到能跑"。
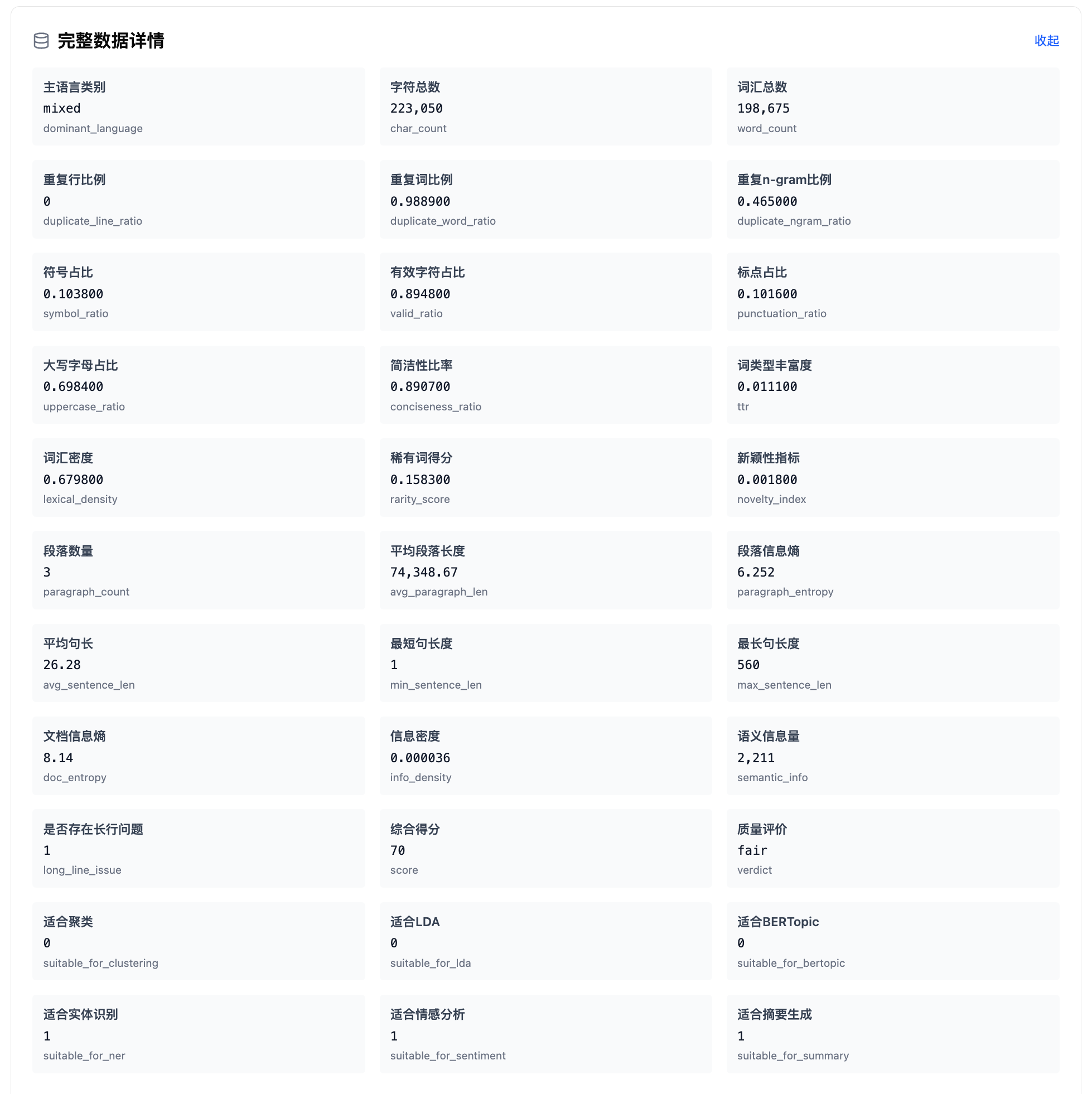
9.NLP 体检——六个指标分组。基础统计展示主语言类别、字符总数、词汇总数、段落数量。重复性指标用进度条展示重复行、重复词、重复 n-gram 三项比例,高重复率往往提示模板化或爬虫噪声,但词典、列表、法律条文等天然高重复的文本不一定低质。文本组成分析展示符号占比、有效字符占比、标点占比、大写字母占比、简洁性比率。词汇质量指标展示 TTR、词汇密度(实词占比)、稀有词得分(只出现一次的词占比)、新颖性。结构特征展示平均段落长度、段落信息熵、句长统计。信息密度展示文档信息熵、信息密度、语义信息量(唯一词数)。
10.完整数据和术语表。报告底部可以展开查看所有原始字段的数值,还有一个可折叠的术语表,包含 30 个统计学术语的解释,遇到不认识的指标可以在这里查。

参数解析与对比示例
文本质量评估器无需手动配置参数,上传文件即可自动评估。以下是评估过程中涉及的核心指标和阈值。
综合得分扣分规则。
| 指标 | 扣分条件 | 扣分值 |
|---|---|---|
| 符号占比 | 超过 30% | -15 |
| 有效字符占比 | 低于 50% | -15 |
| 文本长度 | 不足 800 字符 | -15 |
| 平均句长 | 超过 80 词 | -8 |
| 段落信息熵 | 低于 2.0 | -10 |
| 平均段落长度 | 超过 2000 字符 | -8 |
| TTR | 低于 0.10 | -10 |
| 重复行比例 | 超过 40% | -6 |
| 重复词比例 | 超过 92% | -6 |
| 重复 n-gram 比例 | 超过 85% | -7 |
| 唯一词数 | 低于 50 | -8 |
| 句数 | 低于 3 句 | -8 |
| 自然句占比 | 低于 40% | -10 |
| 长行问题 | 存在超 2000 字符的行 | -6 |
任务适用性判定门槛。
| 任务 | 最低字符数 | 其他要求 |
|---|---|---|
| 聚类 | 150 | 语料合格基线(有效字符 >= 30%、重复 n-gram <= 95%、TTR >= 0.05、唯一词 >= 15) |
| LDA | 100 | 同上 |
| BERTopic | 50 | 同上(门槛最低,因为嵌入模型对短文本鲁棒性更好) |
| 命名实体识别 | 200 | 有效字符 >= 50% |
| 情感分析 | 100 | 有效字符 >= 50% |
| 抽取式摘要 | 400 | 句数 >= 3 且综合评价不是 poor |
两组典型评估结果供参考。
- 良好语料。综合得分 82(good),六种任务全部通过。字符以中文为主(占比 78%),符号占比 5%,TTR 0.42,MTLD 67.3,重复 n-gram 12%,句长分布均匀。可以直接进入下游分析。
- 需清洗语料。综合得分 47(poor),六种任务均未通过。符号占比 38%(爬虫噪声),重复行比例 52%,有效字符不足。需要先做文本清洗去重去噪声,再重新评估。
案例分析
案例一:主题建模前的质量摸底。
背景:某研究者准备用 BERTopic 对 200 篇新闻报道做主题聚类,想先确认语料质量。
操作:上传全部 200 篇文件,跑一次评估器。
结果:综合得分 82(good),任务适用性显示聚类、LDA、BERTopic 三项全部通过。词汇丰富度 MTLD 为 67.3,说明用词多样性不错。重复 n-gram 比例 12%,在合理范围内。多文件对比表显示各文件得分集中在 75-90 之间,没有明显异常文件。研究者放心进入下一步主题建模。
案例二:爬虫数据质量筛查。
背景:某团队从三个不同网站爬取了 300 篇文章,想确认哪些网站的数据质量更好。
操作:三个网站的文本分别上传,横向对比。
结果:网站 A 综合得分 71(fair),重复行比例 38% 偏高,模板化明显,重复性指标分组中重复行进度条接近四成;网站 B 得分 85(good),各项指标健康,字符构成以中文为主、符号占比低;网站 C 得分 54(poor),符号占比 45%,有效字符不足,六种任务全部未通过。团队决定只用网站 B 的数据,网站 A 需要先做文本清洗去重,网站 C 数据质量太差需要重新爬取。
案例三:学术语料库批量审核。
背景:某语言学实验室建了一个 200 篇论文的语料库,需要统一标准筛选合格样本。
操作:上传全部文件,查看综合得分分布和任务适用性。
结果:综合得分中位数 76(good),但有 15 篇综述类文章得分在 55-62 之间(fair 到 poor 边界),MTLD 明显低于实验类文章,句长分布偏向长句(P90 达 62 词)。实验室据此将综述和实验分开建模,聚类效果改善明显。
类似功能对比
文本质量评估器和文本可读性评估容易搞混,其实侧重点不一样。
| 对比维度 | 文本质量评估器 | 信息价值评估器 | 文本可读性评估 |
|---|---|---|---|
| 分析粒度 | 整篇文档 | 逐段/逐行 | 整篇文档 |
| 关注什么 | 文本能不能用于 NLP 任务 | 每段话的信息量够不够高 | 文本对读者来说好不好懂 |
| 核心指标 | 综合得分、任务适用性、重复率、词汇丰富度 | 段落综合得分、信息熵、困惑度、词汇密度、信息密度 | 可读性指数、阅读难度等级 |
| 方法 | 纯统计,零 LLM | 纯统计加可选大模型复核 | 统计加语言学公式 |
| 典型用途 | 跑分析前预检语料质量 | 从长文中筛出信息量高的段落,剔除噪声段落,删除废话 | 评估文章的受众适配度 |
| 输出 | 综合得分 + 六项任务判定 + 六组指标 | 每段得分 + 保留/剔除建议 + 原因标签 | 可读性等级 + 难度评分 |
如果你关心的是"这份语料能不能拿去做分析",用文本质量评估器。如果你关心的是"这篇文章小学生能不能看懂",用文本可读性评估。