传统情感分析功能做的是逐行情感初筛。系统会读取 TXT 的非空行,或读取 CSV 里的文本单元格,把每条文本清理后送入两种词典方法。每种方法都会输出一个 0 到 1 的分数,并把结果归为积极、中性或消极。
两种方法的口径不同。PySenti 主要按正负情感词和权值计算分数,归一化后用 0.45 到 0.55 作为中性区间。CnText 使用内置情绪词典统计情绪词,把积极情绪占比映射成 0 到 1 分数,0.7 及以上为积极,0.4 及以下为消极,中间为中性。因为词典来源和阈值都不一样,同一句文本可能出现不同判断。
报告里的「一致率」就是为这种差异准备的。它统计两种方法在多少行文本上给出相同标签。这个指标不等于准确率,也不表示系统理解了语境;它只说明两套词典口径在这批文本上的一致程度。一致率低时,通常需要回到分歧样本看原文,而不是直接采纳某一套结果。
自定义情感词典是另一个核心能力。用户可以在页面上添加积极词和消极词,用来补充 PySenti 的领域词表。例如课程反馈里的「讲得透」、商品评论里的「回购」可以放到积极词;「节奏乱」「掉漆」「尺码不准」可以放到消极词。它是词表补充,不是训练模型,也不能让系统自动理解反讽、上下文、省略和隐含态度。CnText 仍按内置情绪词典口径计算,不会因为这些自定义词同步改变。
适用文档
课程反馈适合使用。课程开放题里有很多领域表达,比如「讲得透」「案例清楚」「节奏乱」「反馈慢」。这些词未必都在通用词典里,适合通过自定义积极词和消极词补充。
商品评论适合使用。商品评论中的「回购」「耐用」「掉漆」「尺码不准」都有明确业务含义。默认词典可以处理一部分通用褒贬词,自建词典可以补充业务词,再通过两种方法对比结果。
问卷开放题适合做初筛。开放题答案通常短而分散,先分出明显积极、明显消极和中性文本,可以减少后续人工阅读压力。分歧样本适合作为人工编码的重点。
舆情短文本可以使用,但需要谨慎。社交平台文本常见反讽、省略、网络表达和上下文缺失。词典方法对这些内容不敏感,低一致率和分歧样本应当被视为复核入口,而不是最终解释。
访谈材料可以按段使用。长段访谈往往同时包含肯定和批评,不适合整段只贴一个标签。一般先按回答片段或主题段落拆分,再用传统情感分析做粗粒度标注。
文本质量方面,每行最好是一句或一条独立反馈。过短文本会被过滤并记录原因。大量乱码、网页残留、特殊符号会干扰词典匹配,通常先做文本清洗再分析更稳。
使用步骤
第一步:整理文本粒度。把材料整理成每行一句或一条反馈。CSV 文件中系统会遍历文本单元格,TXT 文件按非空行处理。粒度越清楚,后面查看分歧样本越方便。
第二步:决定是否建立情感词表。如果只是通用评论,可以先留空跑默认结果。如果材料属于特定领域,可以先列出明确正向和负向词,再分别填入积极词和消极词。

第三步:提交分析后先看有效行数。有效行数表示进入分析的文本数量,跳过行数表示因为过短等原因没有进入分析的文本。有效文本太少时,分布比例参考价值有限。

第四步:比较 PySenti 和 CnText 均分。两套均分来自不同词典和阈值,不能直接当作同一种量尺比较,只能作为同批次下的方向性参考。真正解读时要结合标签分布和分歧样本。
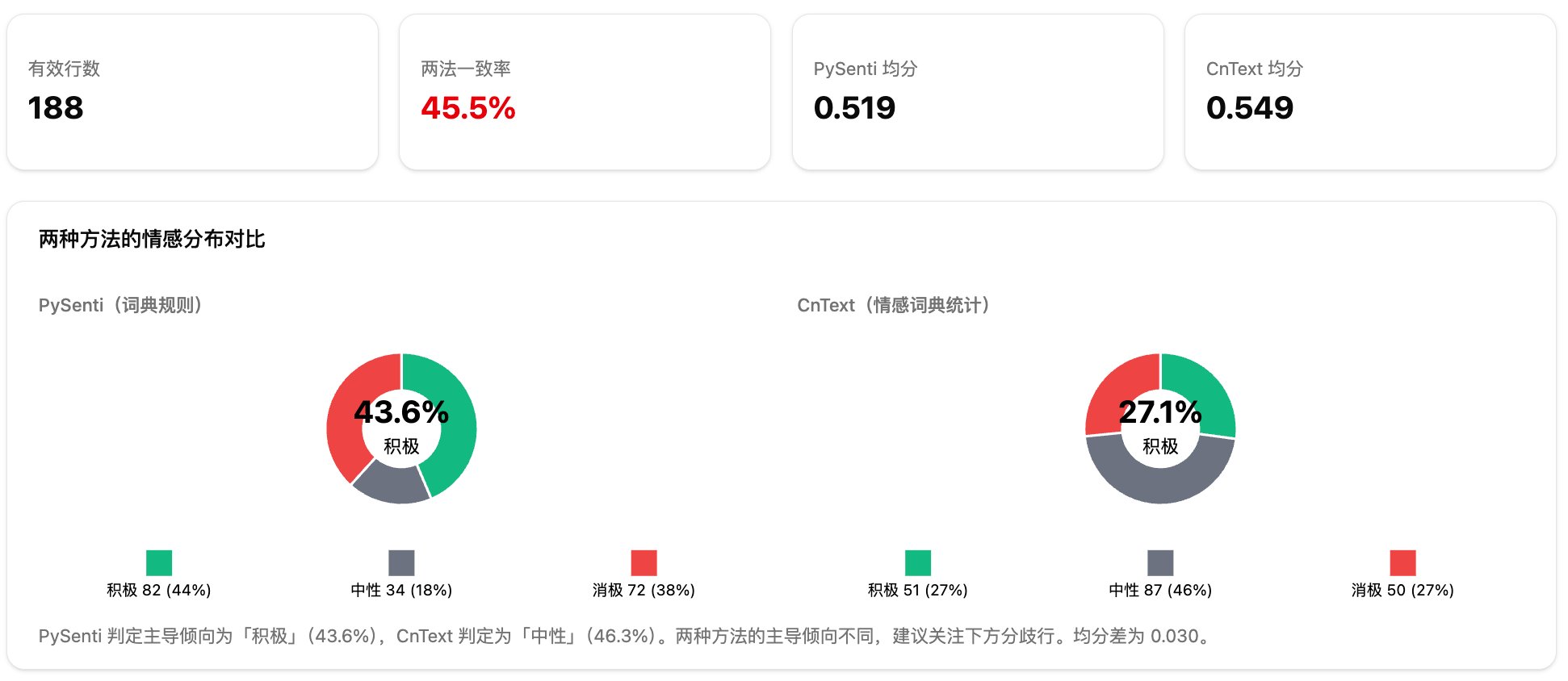
第五步:查看两种方法的情感分布。报告用两张饼图并排展示积极、中性、消极占比。这里不要只看某一张图,而要看两种方法的结构是否接近。
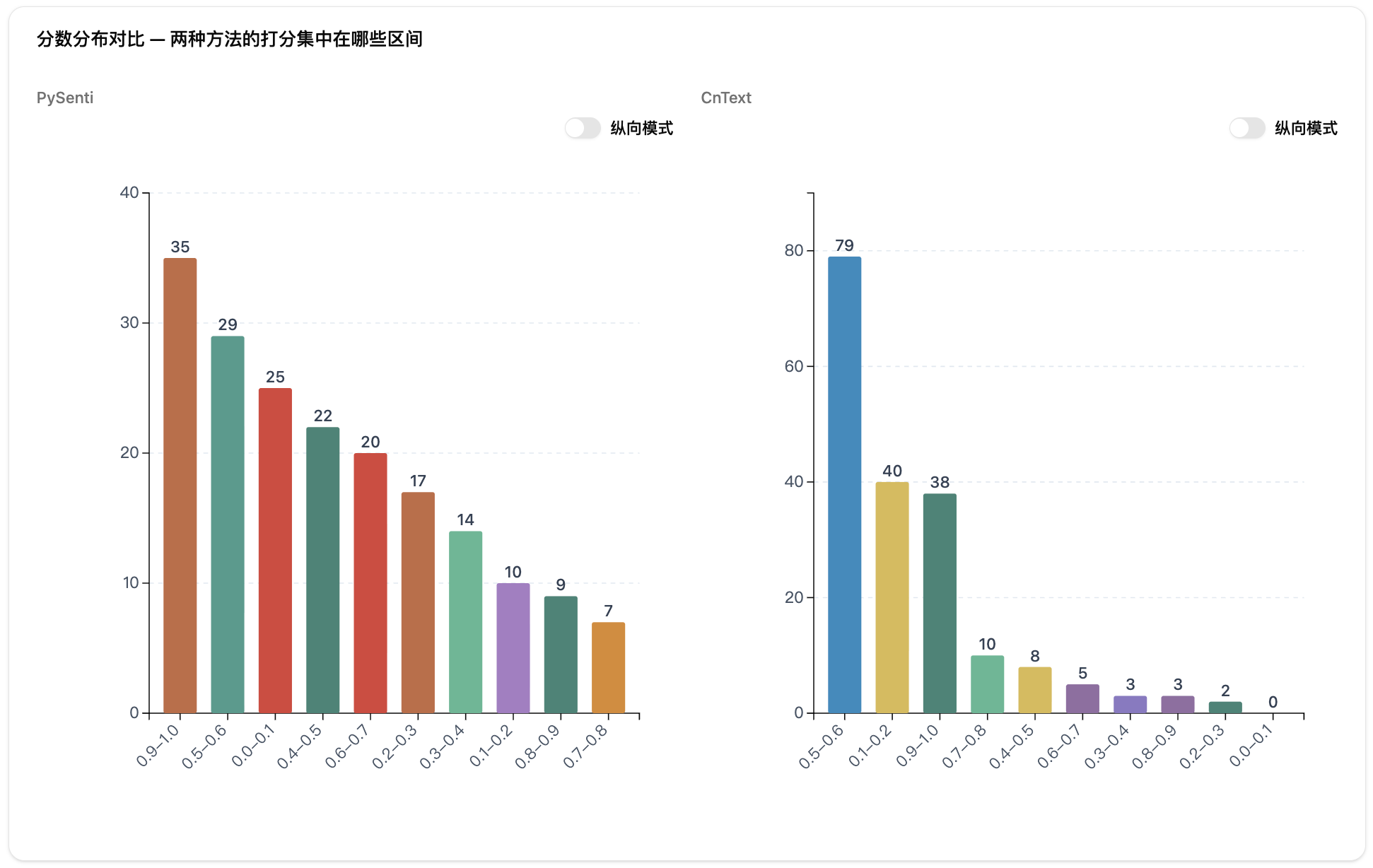
第六步:查看分数分布。柱状图展示分数集中在哪些区间。如果大量文本集中在中间区间,说明词典口径下的态度不够明确,后续解释要更克制。
第七步:查看一致性分析。报告会列出两种方法判断不同的行,包括行号、原文、PySenti 标签和分数、CnText 标签和分数。这部分是最适合人工复核的入口。

第八步:查看热门关键词。报告会分别列出积极关键词和消极关键词。关键词可以帮助你检查词典是否覆盖了重要表达。如果重要业务词频繁出现在原文里却没有被合理体现,可以回到自定义词典补充。补词主要改变 PySenti 口径,不改变 CnText 内置词典口径。

第九步:多文件时切换单文件视图。如果上传了多个渠道、班级或话题的材料,可以先看综合统计,再切换到单个文件查看口径差异。
参数解析与对比示例
可配置和输入项如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 上传文件 | 支持 TXT 和 CSV;TXT 按非空行读取,CSV 遍历文本单元格;可上传多文件 | 必填 |
| 自定义积极词 | 补充明确正向表达,主要影响 PySenti 词典规则口径 | 空 |
| 自定义消极词 | 补充明确负向表达,主要影响 PySenti 词典规则口径 | 空 |
| 邮件通知 | 任务完成后发送通知,适合较大批量文本 | 关闭 |
| 邮件地址 | 开启邮件通知后填写接收地址 | 空 |
三组典型配置供参考。
- 默认词典初筛。积极词和消极词都留空,先查看两种方法的分布和一致率。适合通用评论和没有明确领域词表的材料。
- 课程反馈词表。积极词加入「讲得透」「案例清楚」「互动好」,消极词加入「节奏乱」「反馈慢」「内容浅」。适合课程评价、培训反馈和教学调研。
- 商品评论词表。积极词加入「回购」「耐用」「质感好」,消极词加入「掉漆」「尺码不准」「异味」。适合电商评论和售后反馈。
配置对比时,不建议只比较积极率有没有升高。更合理的读法是:先看 PySenti 结果在补充词典后是否符合业务口径,再看它和 CnText 的差异是否变大或变小,最后抽检分歧样本确认词表是否需要继续调整。
案例分析
案例一:课程开放题补充教学词表。
背景:教务老师收集 430 条课程反馈,默认词典能识别「满意」「差」这类通用词,但对「讲得透」「节奏乱」这类教学表达覆盖不足。
配置:积极词加入「讲得透」「案例清楚」「互动好」,消极词加入「节奏乱」「反馈慢」「内容浅」。
结果:报告展示 PySenti 和 CnText 两套分布、均分和一致率。补充词表后,老师重点查看 PySenti 结果变化,并抽检两种方法判断不同的文本。
结论:通过查看分歧样本和人工复核,老师可以辅助判断问题可能来自词典未覆盖,也可能来自文本本身含糊。前者继续补词,后者进入人工复核。
案例二:商品评论建立业务褒贬词。
背景:运营同事整理 1,200 条商品评论。评论里有「回购」「耐用」「掉漆」「尺码不准」等业务词,默认词典不一定完全符合运营口径。
配置:积极词加入「回购」「耐用」「质感好」,消极词加入「掉漆」「尺码不准」「异味」。
结果:报告列出有效行数、两套方法均分、情感分布、一致率和分歧样本。运营同事没有把某一套结果作为最终答案,而是把分歧样本整理出来给人工抽检。
结论:这个功能适合作为评论初筛和词典调试工具。它能减少人工从零浏览的工作,但不能替代人工判断具体语境。
案例三:舆情短文本先做分歧定位。
背景:研究者收集 2,000 行短帖,文本里有省略、反讽和网络表达。直接看正负面比例风险较高。
配置:先不加自定义词,使用默认词典跑一遍,重点查看一致率和分歧行。
结果:某个话题下两种方法一致率偏低。研究者人工查看分歧样本后,发现其中有不少表面正向、实际可能带反讽的表达。
结论:研究者把这些行标记为人工复核样本,而不是继续用词典结果做最终解释。后续如果发现稳定的领域褒贬词,再补充到自定义词典中重新分析。
类似功能对比
传统情感分析、VAD 三维情感分析、隐含情感识别都和情绪有关,但它们解决的问题不同。
| 对比维度 | 传统情感分析 | VAD 三维情感分析 | 隐含情感识别 |
|---|---|---|---|
| 做什么 | 对比两种词典方法,输出积极、中性、消极 | 从效价、唤醒度、支配度三个维度描述情绪 | 识别字面之外的隐含负面和表达意图差异 |
| 关注点 | 词典口径、一致率、自定义情感词 | 情绪强度和三维位置 | 反讽、捧杀、阴阳怪气 |
| 适合问题 | 这批文本按词典法初筛是什么倾向 | 负面情绪更接近愤怒、焦虑还是无助 | 表面好评里是否有隐藏不满 |
| 输出 | 分布饼图、分数分布、分歧样本、关键词 | 三维分值、情感空间、逐行结果 | 多维评分和问题句 |
| 使用边界 | 不擅长复杂语境理解 | 更适合细分情绪结构 | 更适合隐含表达较多的文本 |
如果你的需求是快速做正负中初筛,并且希望自己维护情感词表,用传统情感分析。如果你需要更细的情绪维度,再考虑 VAD 三维情感分析。如果文本里大量反讽和含蓄表达,隐含情感识别更贴近需求。