命名实体识别做的是对象抽取。系统先读取上传的 TXT 或 CSV 文本,把正文拆成句子,再在句子中识别人名、地名、机构名、时间等实体。每条实体都会保留原句、类型和位置,因此你看到的不只是一个词表,而是一张可以回到上下文的明细表。
报告采用两种识别口径。规则识别偏稳定,适合快速获得常见中文专名线索;语义识别会结合句意判断人物、地理位置、组织机构和时间,边界或数量可能与规则识别不同。两种结果并排显示时,差异不是错误提示,而是提醒你对重要句子做人工复核。
处理时可以上传自定义字典,让领域词或机构简称更容易被完整切分;也可以上传停用词表,过滤不希望进入结果的噪声词。分词模式和词性过滤会影响规则识别结果,尤其是中文文本中专名被切开的情况。长文档为了保证页面可读性,报告页可能只显示前段预览,完整逐条明细仍在下载 CSV 中。
适用文档
文本长度方面,命名实体识别更适合信息密度较高的材料。单篇几百字以上通常更容易出现稳定线索;如果只有一句口号或几个编号,报告可能几乎没有结果。新闻报道、政策文件、访谈记录、舆情评论和研究语料都适合先做实体整理。长文档可以处理,但页面明细会压缩展示,完整结果需要下载 CSV 查看。
文本质量方面,输入应当是可读正文。报告页面明确提示,文件建议使用 UTF-8 编码的 .txt 或 .csv。如果文件为空、编码异常、几乎只有编号,或经停用词过滤后没有可读内容,就可能没有可展示结果。网页抓取文本里如果混入大量导航、页脚、乱码或重复模板,建议先做文本清洗;繁简混用、全半角混乱时,可以先做中文文本规范化。
语言和行业方面,这个工具主要面向包含中文专名的文本。政策文本可以用来整理部门、地区和时间线索;新闻报道可以用来梳理人物、机构和地点;访谈材料可以用来盘点受访者反复提到的对象。领域术语较多时,建议上传自定义字典。例如医院简称、社区名称、项目代号如果经常被切散,自定义字典能帮助规则识别保留更完整的词形。
输入格式方面,工具页面支持 TXT 和 CSV,单文件大小按页面限制执行。TXT 按正文处理;CSV 会读取文本列并进入分析流程。自定义字典和自定义停用词使用 TXT 文件,每行一个词。
使用步骤
第一步:上传文件。进入命名实体识别页面后,上传 TXT 或 CSV 文件。如果是 CSV,通常应选择包含正文的列,避免把编号列、空列或无关字段混入正文。

第二步:配置参数。常规材料可以先保持默认;如果材料里有机构简称、项目名或地名缩写,上传自定义字典;如果有模板词、口头禅或明显无意义词,上传自定义停用词。分词模式、词性过滤和智能词汇识别的细节在下一节说明。
第三步:查看顶部解读。报告完成后,先看顶部结果卡片。这里会概括工具在做什么,并给出实体总量、实体类型数、含实体句占比、规则识别数量和语义识别数量等信息。

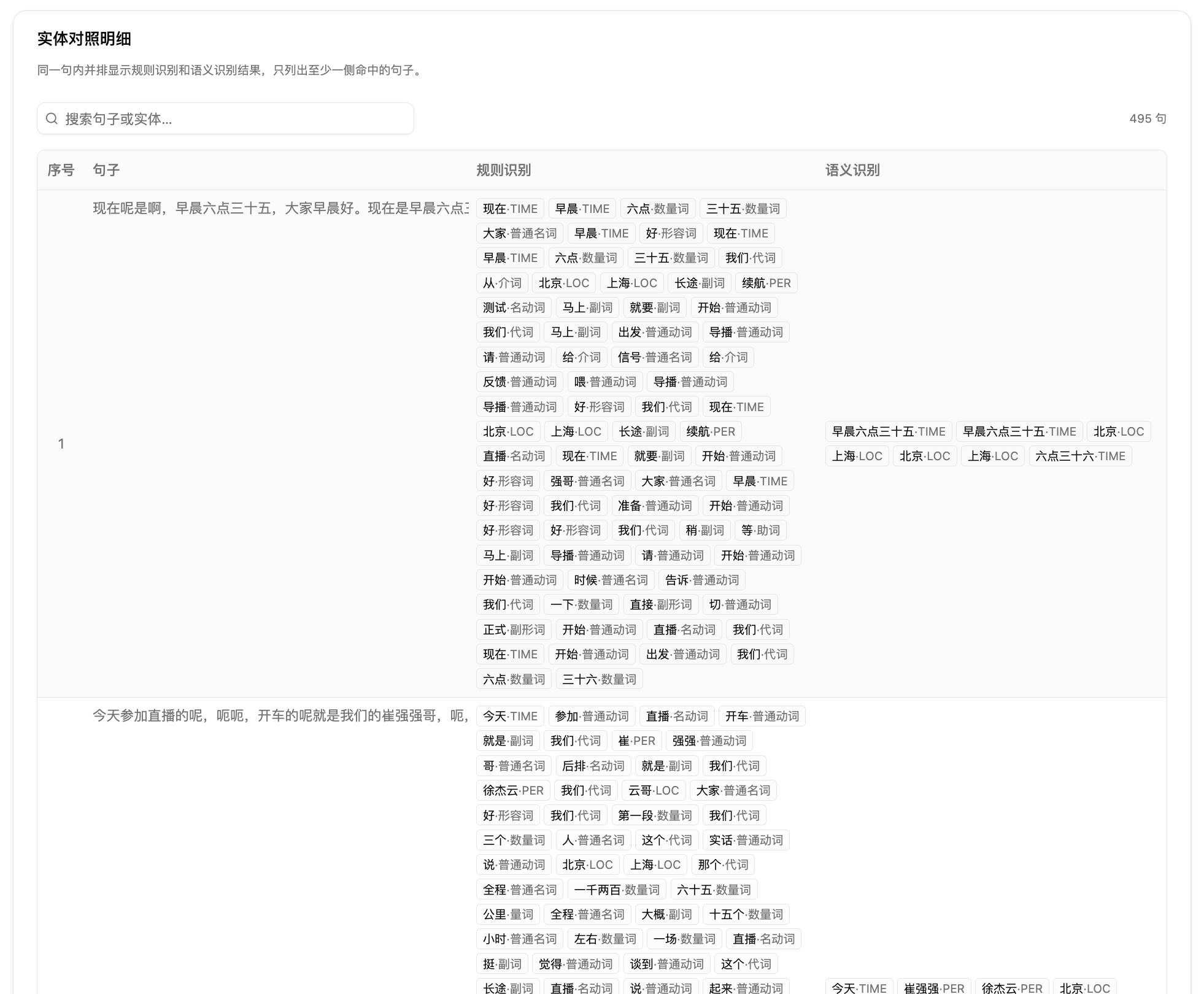
第四步:查看高频实体和对照明细。高频实体卡片分别展示规则识别和语义识别中更集中的实体。实体对照明细按句展示,表格列包括序号、句子、规则识别、语义识别。你可以搜索句子或实体,也可以翻页抽查边界。

第五步:下载结果。下载 CSV 后可以得到实体明细和统计表。实体明细包含原句、词、类型、开始位置、结束位置;统计表包含实体类型数量、总句子数、包含实体的句子数和平均每句实体数等信息。
参数解析与对比示例
可配置参数如下。
| 参数 | 说明 | 默认值 |
|---|---|---|
| 自定义字典 | 上传 TXT 词典,每行一个词,用于辅助领域词、机构简称、地名缩写等内容切分 | 关闭,未上传 |
| 自定义停用词 | 上传 TXT 停用词表,每行一个词,用于过滤模板词、口头禅或无意义词 | 关闭,未上传 |
| 智能词汇识别 | 尝试从语料中发现新词,并作为补充分词词典参与处理;耗时较长,新词不保证单独出现在最终结果里 | 关闭 |
| 分词模式 | 中文分词方式,可选精确模式、全模式、搜索引擎模式;一般先用精确模式 | 精确模式 |
| 词性过滤 | 选中的词性类型会在分词阶段被排除,不参与后续处理;仅适合中文文本 | 关闭 |
| 完成后发送邮件通知 | 任务完成后发送邮件提醒,不影响识别结果 | 关闭 |
三组典型配置供参考。
- 快速新闻梳理。保持默认配置,直接上传新闻报道 TXT 或 CSV。适合先看人物、机构、地点和时间是否集中,再用搜索框核对重点实体。
- 领域材料识别。上传自定义字典,保持精确模式,不开启过多词性过滤。适合政策、医疗、金融、学校或社区材料中存在大量简称和专有名称的情况。
- 访谈或问卷整理。上传停用词表,过滤「这个」「然后」「感觉」等不需要进入结果的词。词性过滤要谨慎使用,不建议把人名、地名、机构团体名等类别排除,否则会影响实体召回。
分词模式会改变规则识别的边界。全模式和搜索引擎模式可能产生更多候选词,也可能带来重复或噪声;如果目标是稳定整理对象清单,建议先用精确模式跑一次,再根据结果决定是否调整。
案例分析
案例一:新闻事件报道梳理。
背景:研究人员收集了 20 篇同一事件的新闻报道,想先整理涉事人物、机构、地点和时间,再做事件线索分析。
配置:保持精确模式,上传包含常见机构简称的自定义字典,不使用词性过滤。
结果:报告顶部先显示实体总量、实体类型数和含实体句占比。高频实体卡片帮助研究人员锁定反复出现的人物和机构。随后在对照明细里搜索 6 个重点机构名,逐句核对规则识别和语义识别的差异。下载的实体明细 CSV 被用于整理人物、机构和地点清单。
结论:命名实体识别把对象整理提前完成,后续再做事件时间线或词语共现时,不需要从原文里反复人工查找同一批名称。
案例二:访谈材料对象盘点。
背景:调研团队整理 60 段访谈文本,受访者反复提到社区、学校、医院和若干具体地点。团队希望先知道哪些对象最常被提到,再进入主题分析。
配置:上传访谈文本 CSV,选择正文列;上传停用词表过滤常见口语词;保持精确模式,不排除人名、地名和机构团体名。
结果:报告中的含实体句占比用于判断材料里对象线索是否足够。团队在实体对照明细中搜索学校和医院名称,查看这些实体出现在哪些句子中。长文档页面只保留前段预览时,团队下载完整 CSV 做后续归类。
结论:先做实体识别有助于把「谁」「哪里」「哪个机构」从主题里拆出来。主题分析负责看议题,实体识别负责整理对象,两者分工更清楚。
类似功能对比
命名实体识别、高频词提取、关键词抽取都能从文本中提取词项,但关注点不同。
| 对比维度 | 命名实体识别 | 高频词提取 | 关键词抽取 |
|---|---|---|---|
| 做什么 | 提取人名、地名、机构名、时间等对象线索 | 统计出现次数较高的词或词组 | 提取更能代表主题的词 |
| 关注点 | 对象、类型、原句位置 | 频次和固定搭配 | 代表性和主题相关性 |
| 报告重点 | 顶部解读、高频实体、实体对照明细 | 词频结果和词组结果 | 关键词列表和权重 |
| 适合问题 | 文本里有哪些人物、地点、机构和时间 | 哪些词被反复提到 | 哪些词概括主题 |
| 后续用途 | 事件梳理、对象清单、共现分析 | 语料概览、提法盘点 | 主题标签、摘要辅助 |
如果你关心的是「材料里有哪些对象」,先用命名实体识别。如果你关心的是「什么词出现得最多」,用高频词提取。如果你关心的是「哪些词最能代表主题」,用关键词抽取。三者可以连续使用,但不要把高频词直接当成实体,也不要把实体数量当成主题重要性。